07. 제네릭과 컬렉션
인프런의 부부 개발단 토토님의 즐거운 자바 강의를 정리한 내용
# 제네릭
# 제네릭이 나온 이유
자바에는 어떤 객체든지 참조할 수 있는 것이 Object이다. 모든 클래스의 최상위 부모가 Object 클래스니까 어떤 객체든 참조할 수 있다. 이를 이용하여 무엇이든 담을 수 있는 상자를 만들어보자.
| |
- 부모 타입으로 자식 인스턴스를 참조하는거니까 Object의 자손은 모~든 클래스니까 아무거나 들어올 수 있겠네
| |
get()은 return 타입이 Object니까 형변환 해준 것- ObjectBox는 어떤 Object든 저장할 수 있고, 어떤 Object든 꺼낼 수 있다.
- 하지만, 꺼내서 사용할 때는 원래 타입으로 변환시키는 번거로운 과정이 필요
# 제네릭 기본/장점
제네릭 기본
- T는 제네릭과 관련된 부분
- 제네릭은 클래스 이름 뒤, 메서드의 리턴타입 앞에 붙을 수 있다
<T>부분은 T라는 이름의 제네릭 타입을 선언한다는 것을 의미- T는 Type의 약자이기 때문에 많이 사용되는 문자이지 꼭 T를 쓸 필요는 X
제네릭의 장점
- 정해진 타입만 사용하도록 강제할 수 있다.
- 타입을 강제함으로써 컴파일할 때 잘못된 타입의 값이 저장되는 것을 막을 수 있다.
| |
- GenericBox 클래스는 아직은 정해지지 않은 T라는 타입을 사용하겠다는 의미
| |
- 이렇게
<String>이라고 해주면 GenericBox의 모든T에 String이 들어가게 된다. - String 박스로 만들었기 때문에
genericBox.set(new Integer(5));와 같이 다른 타입을 넣으려고 하면 컴파일 에러가 발생한다.
# 컬렉션 프레임워크
- Java Collections Framework라고 불리는 Collections API는 Java 2부터 추가된 자료구조 클래스 패키지를 의미한다.
- 자료(Data)를 다룰 때 반드시 필요한 클래스의 모음이다. 반드시 숙지하자.
- 참고로, 자료구조 객체들은 제네릭을 사용하지 않으면 Object 타입을 저장한다.
- 그래서 걍 다 제네릭 쓴다고 이해하자.
- Collection api docs는 여기!
핵심은, 여러 인터페이스들과 그를 구현하는 구현체인 클래스들을 사용하는 것이다.
# 핵심 인터페이스
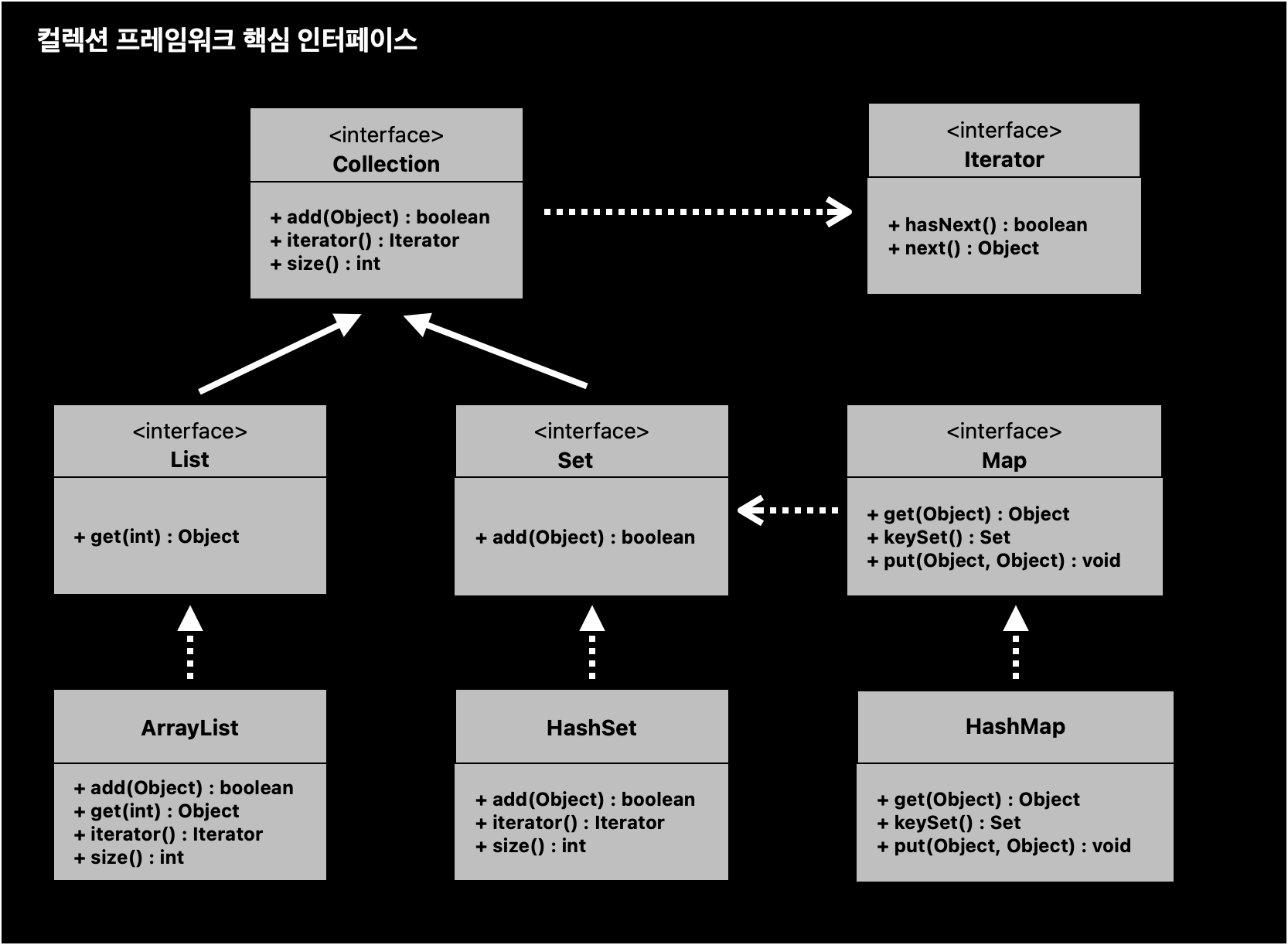
# Collection Interface
Collection 인터페이스 : 여기에 자료가 있다는 것을 표현하는 인터페이스, 바구니
- 컬렉션 프레임워크 중 가장 기본이 되는 인터페이스
- 해당 인터페이스는 순서를 기억하지 않고, 중복을 허용하며 자료를 다루는 목적
add(Object) : boolean바구니에 자료 추가size() : int바구니에 몇 개 있음?iterator() : Iterator바구니에서 반복하여 자료 전부꺼내 - 꺼낼 자료가 있는지 먼저 살핌 - 꺼낼게 있으면 꺼냄 - 꺼낼거 없을 때 까지 두 과정을 계속 반복
# Iterator Interface
Iterator 인터페이스 : 자료구조에서 자료를 꺼내기 위한 목적으로 사용되는 인터페이스
hasNext() : boolean꺼낼거 있는 지 없는지next() : Object하나 꺼내라- 반드시 hasNext로 꺼낼거 있나 없나 체크하고 next로 꺼내기
# List Interface
List 인터페이스 : 순서가 중요한 자료를 다룰 때 사용하는 인터페이스
- Collection 인터페이스를 상속받음, 즉 Collection 인터페이스의 모든 메서드 사용 가능
get(int) : Object순서를 기억하고 있으니까 get으로 순서에 맞게 꺼낼 수 있음
# Set Interface
Set 인터페이스 : 중복을 허용하지 않는 자료를 다룰 때 사용하는 인터페이스
- Collection 인터페이스를 상속받음, 즉 Collection 인터페이스의 모든 메서드 사용 가능
- 중복을 허용하지 않음 = 같은 값을 저장할 수 없음
add(Object) : boolean같은 값은 무조건 1개만 저장- Set 인터페이스에 저장되는 객체들은 Object가 가지고 있는
equals()메서드,hashCode()메서드를 오버라이딩 해야한다.
# Map Interface
Map 인터페이스 : key-value로 구성된 자료구조 인터페이스
- 같은 Key 값으론 하나의 값만 저장 가능
put(Object, Object) : voidMap 자료구조는 put으로 자료를 저장한다.- 앞에 Obejct가 key
- 뒤에 Object가 value
get(Object) : Objectkey값을 넣어서 그에 해당하는 value 꺼냄- key에 해당하는 value 없으면 null 반환
keySet() : Setkey는 유일하기 때문에 key만 모아놓으면 중복되지 않으니까 그게 바로 Set 자료구조가 된다. 그래서 Set 자료구조에 의존함
# ArrayList Class
ArrayList 클래스
- List 인터페이스를 구현한 클래스
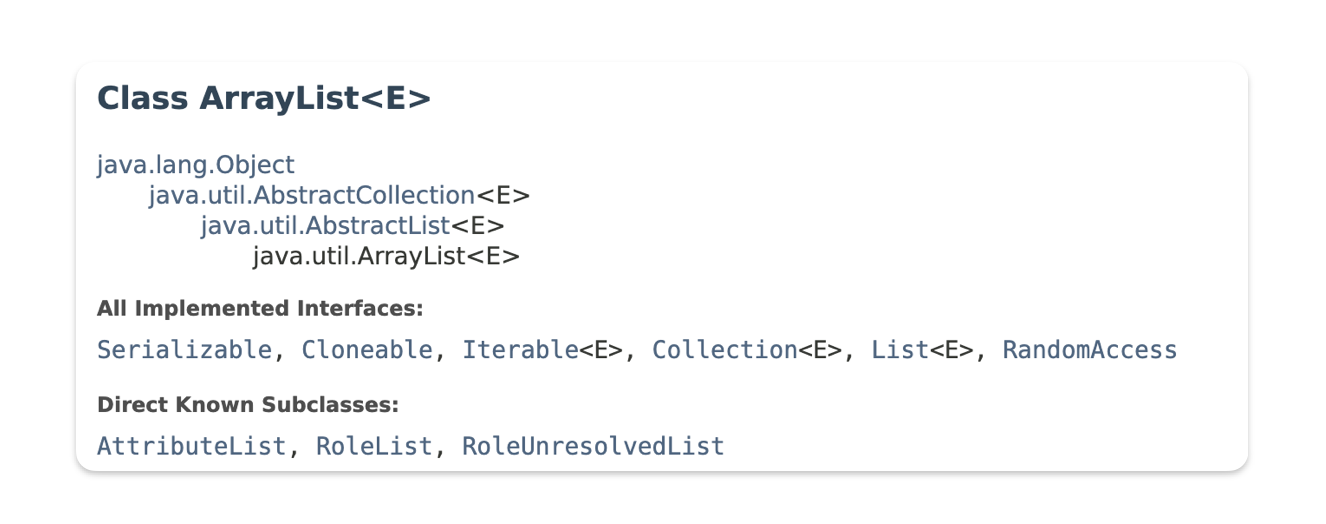
- 클래스 뒤에
<E>Element라는 뜻의 제네릭 표시가 되어있다. - 아직 타입이 정해져있지 않은 것들을 List 형태로 여러 개 가질 수 있는게 ArrayList
제네릭을 사용하지 않고 ArrayList 사용해보기
- 제네릭 안쓰니까 Object로 저장됐음. 그래서 형변환 해주는거
| |
제네릭과 함께 ArrayList 사용해보기
- 꺼낼 때 형변환 안해도 되고 너무 편하다 그죠잉~?
| |
# HashSet Class
HashSet 클래스 : Set 인터페이스를 구현한 클래스
- HashSet에 자료를 저장하려고 하면 자료가 가지고 있는
hashCode()메서드를 먼저 호출한다. 예를 들어, A를 저장하려고 한다면 A의 hashCode 값을 먼저 구한다. - hashCode 값이 “가"라고 한다면 “가” 바구니를 하나 만들고 안에 A를 넣는다.
- B를 저장하려고 하면 B의 hashCode 값을 구한다. 값이 “나"라면 “나” 바구니를 만들고 바구니에 B를 넣는다.
- 그런데 만약, C를 저장하려고 C의 hashCode 값을 구하니 A와 동일하게 “가"가 나왔다고 하자. 그러면
eqauls()메서드를 이용하여 C와 A를 비교한다. 같은 값을 가지지 않는다고 하면 C를 “가” 바구니에 저장한다. - 이러한 과정을 Hash(해시) 알고리즘이라 한다.
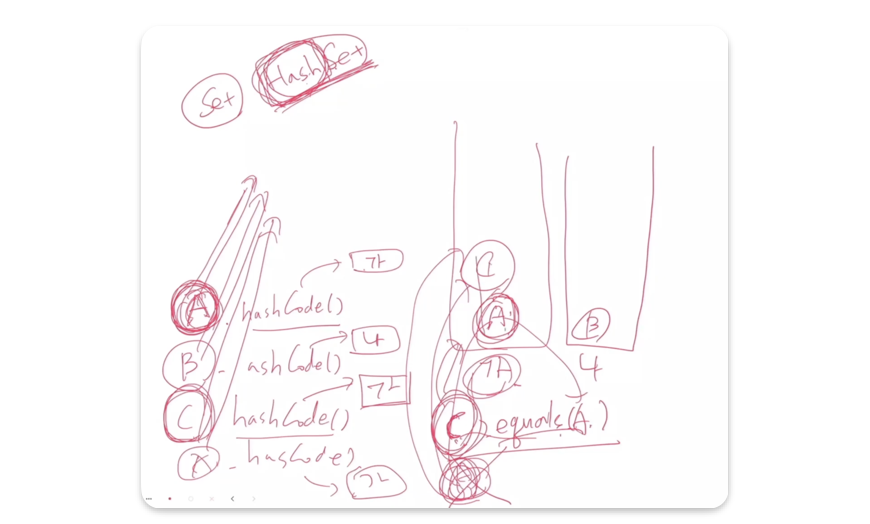
- 성능이 가장 좋으려면 hashCode 값이 다 달라야 한다.
equals()로 값이 동일한지 하나하나 비교하는 과정에서 시간이 오래걸리기 때문이다.
| |
| |
- 중복이 있는데도 왜 들어갔지? 라고 생각하면 안된다.
- 내부적으로
hashCode()메서드 ->equals()메서드를 사용하며 값이 동일한지 아닌지 비교를 하게 된다. - 하지만, 현재 MyData 클래스는
hashCode(),equals()메서드를 오버라이딩 하지 않았기 때문에 부모인 Object 클래스의 것을 사용한다. 04. 객체지향 2/3에서 말한 것처럼 Object의 것은 아무것도 검사해주지 않아서 쓸모가 없기 때문이다.
| |
- 이는 인텔리제이 자동완성 짱짱맨으로 메서드 오버라이딩 한 결과물이다.
# HashMap Class
HashMap 클래스
- Map 인터페이스를 구현한 클래스
- 참고로 Map의 key가 유일한 값을 가져야하니까 key를 저장할 때 Hash 알고리즘이 사용되는데
hashCode(),equals()메서드를 오버라이딩 해줘야하고 String 값이 key가 될 수 있는 것은 String 클래스도hashCode(),equals()를 구현하고 있기 때문에 그런 것이다.
| |
- key가 동일하면 기존의 값을 덮어쓰는 것을 확인할 수 있다.
| |
- map에 있는 모든 값을 출력하고 싶어서, map이 가지고 있는 모든 key에 접근할 수 있는
map.keySet()메서드를 이용했다. 이는 Set 자료구조니까 Set 타입의 keySet에 저장 - key 들이 모이면 Set 자료구조 -> Set 자료구조에서 모든걸 꺼내려면 iterator -> map에서 value를 꺼낼때는
get(key)를 이용
# 컬렉션 사용 Tip
애초에 컬렉션 프레임워크를 만들 때, 자료구조에 대해서 반영했을 것이다. 자연스럽게 자료구조가 가지는 기능을 도출해냈을 것이고 이는 인터페이스의 출현과 관련이 있다. 그리고 이 인터페이스를 구현해주는 클래스가 나오게 됐을 것이다.
그래서 클래스를 이용할 때는 인터페이스를 사용한다는게 객체지향적으로 너무 자연스러운 것이다.
- 컬렉션을 사용할 때는 인스턴스가 무엇이 되든 인스턴스를 사용하고자 하는 목적에 맞는 인터페이스 타입으로 참조하도록 훈련해야한다.
- 먼 훗날에 성능 좋은 클래스가 나오면 그걸로 갈아끼우기만 하면 되니까.
- 참조 타입을 인터페이스로, 인스턴스 타입을 클래스로!
| |
인터페이스 타입 : Collection, 클래스 타입 : ArrayList
| |
- ArrayList 클래스는 List 인터페이스를 구현 -> List 인터페이스는 Collection 인터페이스를 상속받음 -> 부모 타입을 참조 타입으로 하고 자식 인스턴스 참조 가능!
- Collection과 List는 인터페이스니까 ArrayList 클래스의 인스턴스를 생성해서 참조하도록 함
- 인터페이스는 인스턴스화 못하니까
new Collection();못하잖아 - 대신 이렇게 했으니 ArrayList, List가 가진 메서드인
get()을 이용하여 순서로 뽑아내는건 못하겠네. Collection이 가진 메서드만 사용 가능 - 근데 출력을 보면 저장한 순서대로 나오는 걸 볼 수 있음. 이건 Collection을 구현하는게 ArrayList라서 그렇다. 실제로
collection.iterator()부분의 iterator를 구현한건 ArrayList가 메서드 오버라이딩하여 구현했을거니까. - 실제로
new ArrayList<>();를new HashSet<>();으로 바꾸고 출력 결과를 보면 순서가 보장되어있지 않음.
- 인터페이스는 인스턴스화 못하니까
Collection<E> = new ArrayList<>();와 같이 왜 쓰는지 다시 말해보면,
- 이렇게 Collection 인터페이스를 구현한 객체가 저렇게 많다.
- 저들 각각의 메서드와 사용법을 전부 외우기 vs Collection 인터페이스의 메서드 외우기 뭐가 낫겠는가? 당연히 후자가 편하지.
인터페이스 타입 : List, 클래스 타입 : ArrayList
| |
- 이렇게 인터페이스 타입인 List로 바꾸면 ArrayList보다 더 나은 객체가 나오면 그걸로 갈아끼우기만 하면 된다.
# 정렬, 섞기
- 자료구조에서 유용한 메서드들을 모아놓은 Collections 클래스라는게 있다. Collection 인터페이스랑은 다른거다.
- Collections 클래스의 다양한 메서드를 사용해보자.
Collections.sort(리스트) - 리스트 정렬
| |
- 배열을 정렬할 때는
Arrays.sort()와 같이 사용했었는데Collections.sort(list)와 같이 하면 객체들이 정렬된다.
앞에서도 말했지만, 정렬이 되기 위해서는 Comparable 인터페이스를 구현해야만 정렬이 된다. Comparable 인터페이스의 compareTo() 메서드 오버라이딩을 해야하기 때문이다. 현재는 String 객체를 정렬하고 있는데 String 클래스는 내부적으로 Comparable을 구현하고 있기 때문이다.


Collections.shuffle(리스트) - 리스트 랜덤하게 섞기
| |
참고로 배열과 리스트의 차이는 고정이냐 가변이냐이다.
앞에서 배열을 다룰 때는 방의 크기를 정하고 사용했었는데 (고정)
컬렉션에서 리스트를 다루면서 크기를 정한적 없지않느냐. (가변)