SQL코테 - 문법설명
Last updated -
2024년 11월 21일
Edit Source
패스트캠퍼스 핵심유형 20개로 한 번에 끝내는 알고리즘 코딩테스트 with Java 강의를 정리한 내용
본 내용은 PostgreSQL 기준으로, MySQL과 차이가 있을 수 있음
# 기본 문법
# 기본검색 및 정렬 (SFWO)
1
2
3
4
| SELECT [속성명(s)] (","를 통해서 구분)
FROM [테이블명]
WHERE [조건(s)] (and, or 연산자를 통해서 구분)
ORDER BY [속성명(s)] (","를 통해서 구분)
|
SELECTFROMWHERE- FROM 절에서 나열한 테이블, SELECT 절에서 나열한 속성을 토대로 어떤 조건으로 추출할 것인지 조건
ORDER BY- SELECT 절에서 나열한 속성들을 FROM 절에서 명시한 테이블 내 속성 중 어떤 속성으로 정렬하여 보여줄지
# 그룹제어 (GROUP BY)
1
2
3
4
5
| SELECT [GROUP BY에서 사용된 속성명(s), 집계함수]
FROM [테이블명]
WHERE [조건(s)]
GROUP BY [속성명(s)] (","를 통해서 구분)
HAVING [GROUP BY절에 해당하는 조건들] (","를 통해서 구분)
|
GROUP BY- 앞의 검색으로 얻은 데이터들을 특정 조건으로 그룹화하여 데이터를 추출
- 주의) SELECT 절에 나열되는 속성들은 GROUP BY에서 사용한 속성들만 사용 가능
- GROUP BY에서 사용하지 않은 속성들을 사용하고 싶으면 필요에 따라 집계 함수를 SELECT 절에서 표현하여 사용 가능
HAVING- GROUP BY로 생성된 그룹에 대하여 임의의 조건을 명시
- 주의) HAVING 절에서도 GROUP BY에 명시된 속성만 사용 가능
- WHERE 절과 가장 큰 차이는 HAVING 절은 집계 함수를 사용하여 조건을 표현할 수 있다는 점
- WHERE 절에서의 조건을 만족하는 데이터들에 대하여
- GROUP BY로 그룹화 하고
- 해당 그룹에 HAVING을 통해서 조건을 명시하여 데이터 추출
# 분기문 (IF / CASE WHEN)
- 기본적으로
CASE - WHEN - THEN - ELSE - END의 구조- MySQL은 CASE WHEN 대신
IF 함수 사용 가능
1
2
3
4
5
| -- MYSQL에만 IF문 존재
SELECT IF(5-3 > 0, 'TRUE', 'FALSE');
-- PostgreSQL
SELECT CASE WHEN 5 - 3 > 0 THEN 'TRUE' ELSE 'FALSE' END;
|
- 간단한 case 표현식
1
2
3
4
5
6
7
8
9
10
11
| SELECT
(CASE [속성명] WHEN [비교값1] THEN [반환값1]
WHEN [비교값2] THEN [반환값2]
WHEN [비교값3] THEN [반환값3]
WHEN [비교값4] THEN [반환값4]
WHEN [비교값5] THEN [반환값5]
.
.
ELSE [WHEN절 이외의 조건일때 반환될 값]
END) AS [별칭 속성명]
FROM [테이블명]
|
CASEWHENTHEN- CASE의 속성과 WHEN의 비교가 참이라면 반환할 값
ELSEEND
- 검색된 케이스 표현식
1
2
3
4
5
6
7
8
9
10
11
| SELECT
(CASE WHEN [조건문1] THEN [반환값1]
WHEN [조건문2] THEN [반환값2]
WHEN [조건문3] THEN [반환값3]
WHEN [조건문4] THEN [반환값4]
WHEN [조건문5] THEN [반환값5]
.
.
ELSE [WHEN절 이외의 조건일때 반환될 값]
END) AS [별칭 속성명]
FROM [테이블명]
|
# 집합연산 (UNION)
UNION은 두 개 이상의 쿼리 결과를 하나로 합쳐주는 집합 연산자
- UNION 사용 조건
- 합쳐주는 SELECT 부분의 반환 속성 개수와 순서가 모든 쿼리에서 동일해야함
- 각 속성의 데이터 형식이 서로 호환되어야 함
- UNION
1
2
3
4
5
6
7
8
9
| SELECT [속성1]
,[속성2]
,[속성3]
FROM [테이블명1]
UNION
SELECT [속성1]
,[속성2]
,[속성3]
FROM [테이블명2]
|
- 합쳐지는 SELECT 구문 중 중복되는 값이 있으면 중복을 제거하고 결과 보여줌
- UNION ALL
1
2
3
4
5
6
7
8
9
| SELECT [속성1]
,[속성2]
,[속성3]
FROM [테이블명1]
UNION ALL
SELECT [속성1]
,[속성2]
,[속성3]
FROM [테이블명2]
|
# 순위집계 (RANK)
- 그룹별 랭킹을 안넣고 싶으면
PARTITION BY 빼도 됨
- RANK : 동일한 값에 대하여 동일한 순위 부여하고 건너뛰기
1
2
3
4
5
6
7
8
| SELECT RANK() OVER(
PARTITION BY [그룹화할 속성들]
ORDER BY [순위를 매길 때 사용할 속성들]
)
FROM [테이블명1]
-- 예) 1등(100점), 2등(90점), 3등(85점), 3등(85점), 3등(85점)
-- 6등(80점), 7등(79점) ...
|
- 3등이 3명이면 3등을 3명에게 부여하고, 다음 순위는 6등
- DENSE_RANK : 동일한 값에 대하여 동일한 순위 부여하고 건너뛰기 X
1
2
3
4
5
6
7
8
| SELECT DENSE_RANK() OVER(
PARTITION BY [그룹화할 속성들]
ORDER BY [순위를 매길 때 사용할 속성들]
)
FROM [테이블명1]
-- 예) 1등(100점), 2등(90점), 3등(85점), 3등(85점), 3등(85점)
-- 4등(80점), 5등(79점) ...
|
- 3등이 3명이면 3등을 3명에게 부여하고, 다음 순위는 차례대로 4등을 부여
- ROW_NUMBER : 동일한 값에 대해서도 고유한 순위 부여
1
2
3
4
5
6
7
8
| SELECT ROW_NUMBER() OVER(
PARTITION BY [그룹화할 속성들]
ORDER BY [순위를 매길 때 사용할 속성들]
)
FROM [테이블명1]
-- 예) 1등(100점), 2등(90점), 3등(85점), 4등(85점), 5등(85점)
-- 6등(80점), 7등(79점) ...
|
- 85점이 동일하게 3명인데도 각각 3등, 4등, 5등의 고유한 순위 부여
# 조인 (JOIN)
- INNER JOIN
- 결과값을 결합하는 두 테이블 간에
ON 절에 명시된 속성으로 양 쪽 모두 존재하는 데이터들만 결합하는 방법 INNER 문구는 생략해도 됨
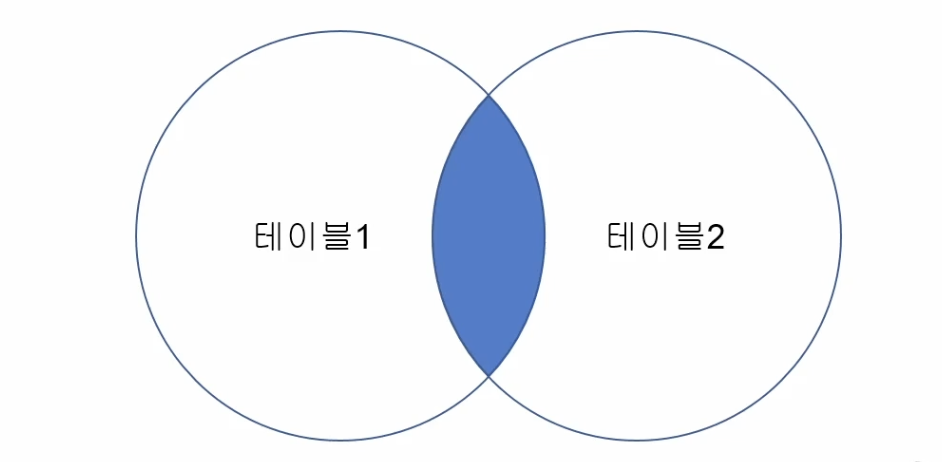
1
2
3
4
| SELECT *
FROM [테이블1] AS A
INNER JOIN [테이블2] AS B
ON A.KEY = B.KEY
|
- OUTER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- 어디에 더 기준을 둘 것이냐에 따른 차이
- LEFT면 왼쪽꺼 전부 결과에 추가 (null도)
- RIGHT면 오른쪽꺼 전부 결과에 추가 (null도)
- OUTER 생략하고 써도 무방
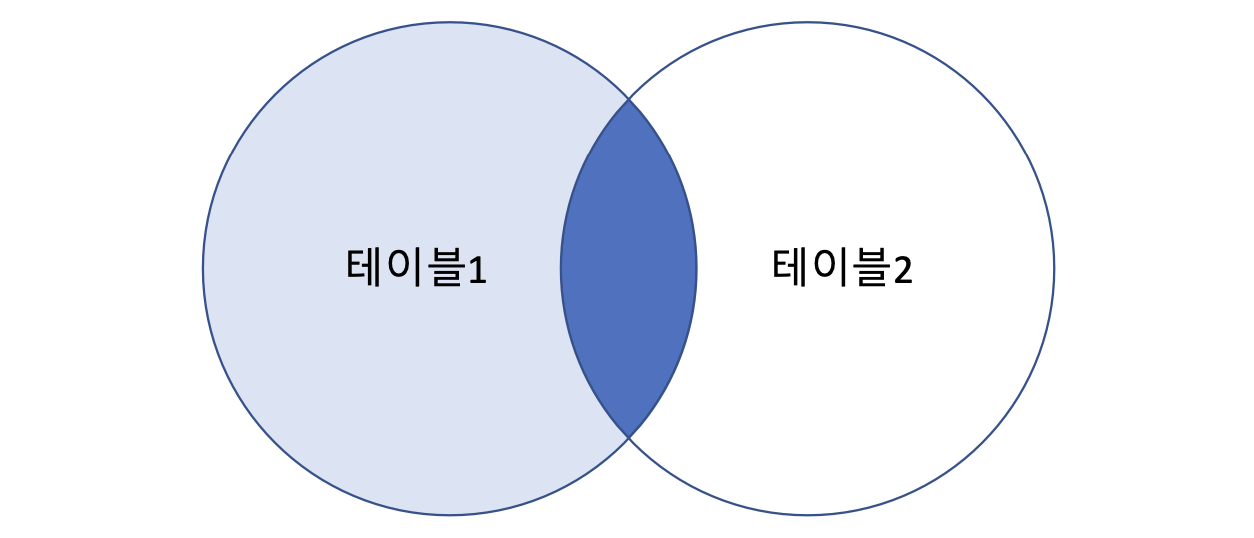
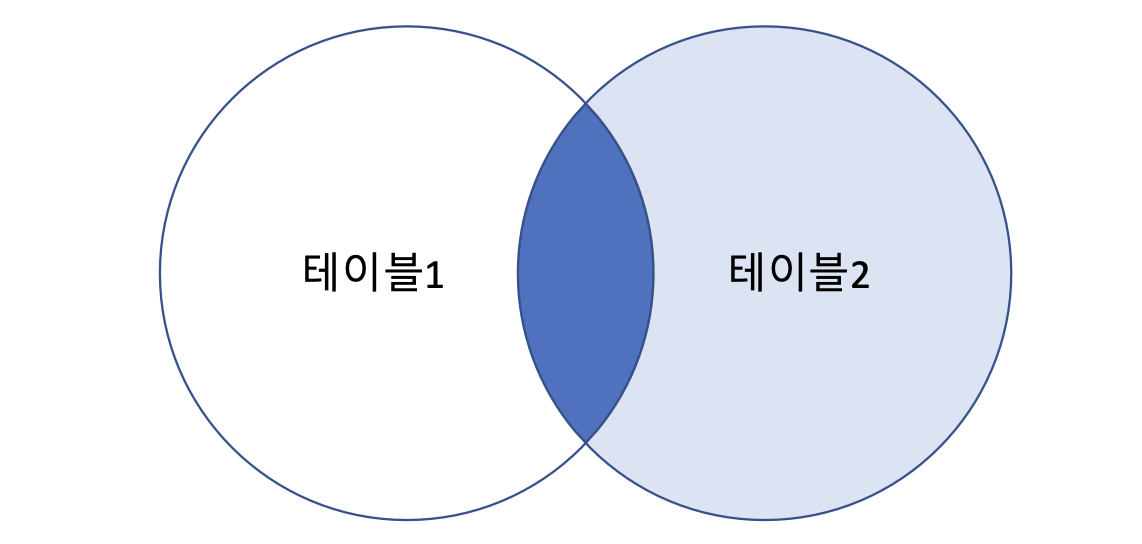
1
2
3
4
5
6
7
8
9
10
11
| -- LEFT OUTER JOIN
SELECT *
FROM [테이블1] AS A
LEFT OUTER JOIN [테이블2] AS B
ON A.KEY = B.KEY
-- RIGHT OUTER JOIN
SELECT *
FROM [테이블1] AS A
RIGHT OUTER JOIN [테이블2] AS B
ON A.KEY = B.KEY
|
- FULL OUTER JOIN
- 좌측의 테이블 1을 기준으로 우측에 테이블 2를 붙이는 결과값
- MySQL은 FULL OUTER JOIN 없음
- LEFT OUTER JOIN, RIGHT OUTER JOIN을 UNION해서 써야함
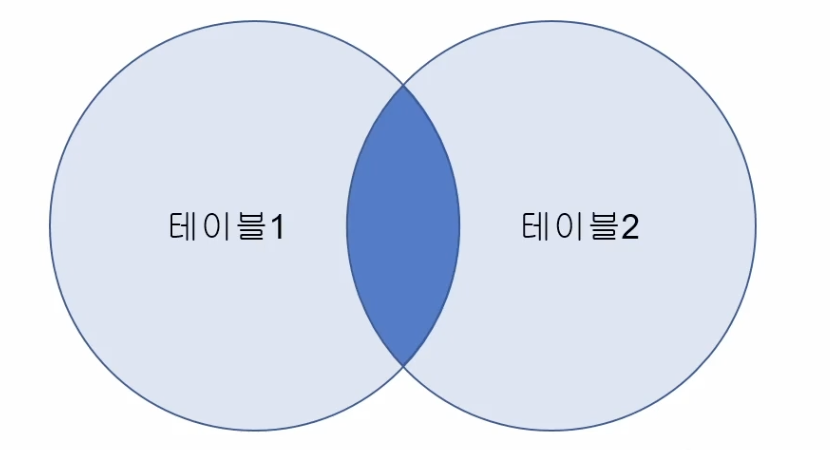
1
2
3
4
| SELECT *
FROM [테이블1] AS A
FULL OUTER JOIN [테이블2] AS B
ON A.KEY = B.KEY
|
- SELF JOIN
- 자기 자신과 조인
- 하나의 테이블에 같은 데이터가 존재하면서 의미가 다르게 존재하는 경우 활용 가능
- 주의) 좌측, 우측 테이블 명이 같으니까 꼭 별칭 써서 구분하기
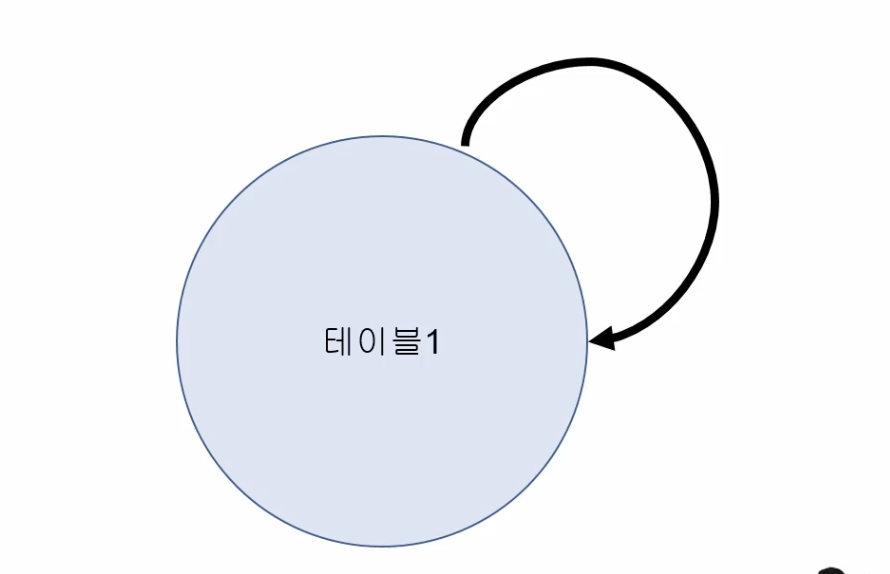
1
2
3
4
| SELECT *
FROM [테이블1] AS A
JOIN [테이블1] AS B
ON A.NAME = B.MANAGER
|

- ex) 하나의 테이블의 직업명이라는 속성에 “김갑수"라는 값이 존재하고 관리자명이라는 속성에도 “김갑수” 값이 존재할 경우, 위와 같이 사용 가능
- 이렇게 하면, 관리자인 김갑수가 관리하는 직원의 이름 추출 가능
- CROSS JOIN
- 연결하는
ON 절 없이 두 테이블을 결합하여 모든 경우의 수가 발생하는 조인 - 다른 말로 카테시안 곱
- MySQL에서는
cross join = inner join = join 이다.- 원래는 cross join에 join condition이 따로 없으니까
ON or USING을 쓰면 안되는데 MySQL에서는 된다. - cross join에
ON or USING을 같이 쓰면 inner join으로 동작함 - inner join (or join) 이
ON or USING 없이 사용된다면 cross join으로 동작함
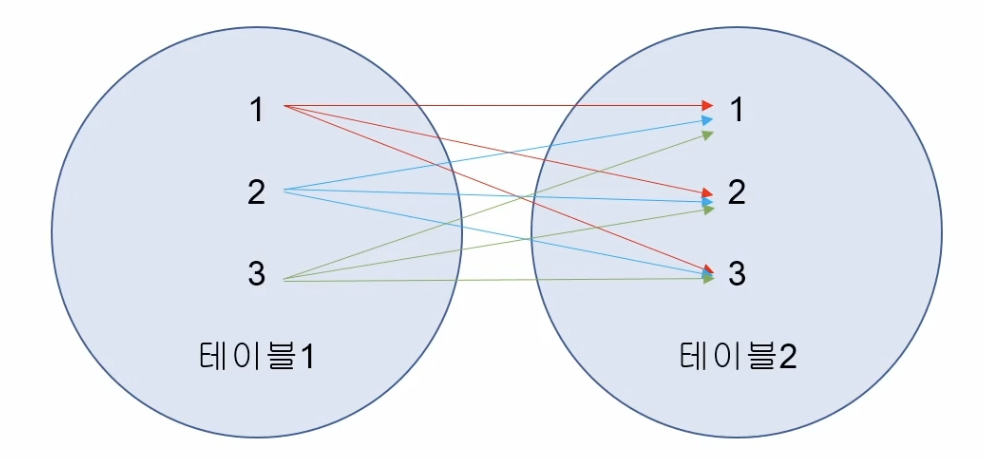
1
2
3
| SELECT *
FROM [테이블1] AS A
CROSS JOIN [테이블2] AS B
|
# 함수
# 집계 함수
MAX([속성명])
MIN([속성명])
COUNT([속성명])
- 명시된 속성 내 값의 전체 행 수를 반환 (NULL값 제외)
SUM([속성명])
- 명시된 속성의 데이터 타입이 숫자일 경우, 해당 속성 내 모든 데이터의 합 반환 (NULL값 제외)
AVG([속성명])
- 명시된 속성의 데이터 타입이 숫자일 경우, 해당 속성 내 모든 데이터의 평균 반환 (NULL값 제외)
# 문자열 함수
SUBSTRING(string, int, int)
- 명시한 문자열 첫 번째 int 부터, 두 번째 int의 개수만큼 부분 문자열을 잘라오기
LTRIM(string), LTRIM(string, string) / RTRIM(string), RTRIM(string, string)
- 명시한 문자열의 좌측/우측 공백을 제거 , 특정 문자 제거
- 중간 중간 공백을 제거하는 것 ❌
- 첫 번째 string부터 문자열 안에 두 번째 string이 포함되어있다면 이를 제거
LPAD(string, n, string) / RPAD(string, n, string)
- 첫 번째 명시한 문자열에 길이가 n 이 되도록 좌측/우측부터 세 번째 명시한 문자열로 채운 표현식을 반환
REPLACE(string, string_pattern, string_replacement)
- 첫 번째 명시된 문자열 중 string_pattern에 해당하는 문자열을 string_replacement문자열로 변환한다.
LENGTH(string)

# 날짜 함수
NOW()
AGE(timestap, timestap) / AGE(timestap)
- 두 날짜 사이의 시간 차이를 계산 / 현재 날짜와 첫 번째 명시한 날짜의 시간 차이를 계산
- PostgreSQL에만 있는거임
- MySQL의 날짜 시간차이 그냥 여기꺼 보셈
DATEDIFF(timestap, timestap)TIMESTAMPDIFF(형식, 앞날짜, 뒤날짜)- 형식에는 year(년), quarter(분기), month(월), week(주), day(일), hour(시), minute(분), second(초)가 가능
1
2
3
4
5
| SELECT DATEDIFF('2023-04-19 11:44:59', '2023-04-01 00:00:00');
-- 결과 : 748
SELECT TIMESTAMDIFF(minute, '2023-04-01 00:00:00', '2023-04-19 11:44:59');
-- 결과 : 1077824
|
DATE_PART(text, timestamp)
- 두 번째 명시한 timestamp에서 첫 번째 명시한 날짜 키워드 인자에 해당하는 값을 추출
DATE_TRUNC(text, timestap)
- 두 번째 명시된 timestamp에서 첫 번째 명시한 날짜 키워드 인자에 해당하는 값 이하의 날짜데이터를 Default처리하고 반환
# 그외 함수
TO_CHAR(timestap, text)- 첫 번째로 명시된 timestamp 값을 두번째 인자의 포맷 문자열로 변환하여 반환
- MySQL은 이거 없음
DATE_FORMAT(날짜, 포맷)
MySQL 포맷
| 결과 | DATE_FORMAT |
|---|
| 연도(4자리) | %Y |
| 연도(2자리) | %y |
| 월(1~12) | %m |
| 월(Jan~Dec) | %b |
| 월(January~December) | %M |
| 일(1~31) | %d |
| 일(Sun~Sat) | %a |
| 시간(0~23) | %H |
| 시간(1~12) | %h |
| 분(0~59) | %i |
| 초(0~59) | %s |
1
2
3
| -- MySQL
SELECT DATE_FORMAT(now(), '%Y-%m-%d');
>> 2023-04-27
|
COALESCE(value, ex1, ex2, ...)
- 첫 번째로 명시된 인자가 null일 경우 두 번째 인자를 반환, 두 번째인자가 null일 경우 세 번째 인자를 반환… 순차적으로 반환
CAST(source_type as target_type)
- 첫 번째 명시된 source_type을 두 번째 인자로 명시된 target_type으로 변환하여 반환
- MySQL에서 CAST 함수로 날짜 간격을 직접 계산하는 것은 지원X
- BETWEEN을 이용한 비교 정도는 괜찮음. 3번문제 참조
- 날짜 간격 계산하고싶으면
DATE_SUB() 써라.DATE_SUB(기준날짜, INTERVAL 1 SECOND)DATE_SUB(기준날짜, INTERVAL 1 MINUTE)DATE_SUB(기준날짜, INTERVAL 1 HOUR)DATE_SUB(기준날짜, INTERVAL 1 DAY)DATE_SUB(기준날짜, INTERVAL 1 MONTH)DATE_SUB(기준날짜, INTERVAL 1 YEAR)DATE_SUB(기준날짜, INTERVAL -1 YEAR)
ROUND(v numeric, s int)
- 첫번째 명시된 v 값을 소수점 s자리까지 반올림하고 s자리 미만은 버림
- MySQL에는
TRUNCATE()도 있는데, 이건 반올림안하고 무조건 버리는거