8주차 - Spring JPA
8주차 스터디
TOPIC
- OSIV
- JPA
- N+1 문제
- fetch join 한계
- OneToMany fetch join 페이징 쿼리 성능 이슈
- MultipleBagFetchException
- OneToOne 양방향 관계 Lazy 로딩 주의
- 상속관계 매핑
# OSIV
OSIV(Open Session In View)는 영속성 컨택스트를 View 단까지 열어준다는 의미이다.
- Spring에서 Presentation Layer(View, Controller)에는 트랜잭션이 없기 때문에 엔티티를 수정할 수는 없다.
- Spring에서는 OSIV 기능이 default로 켜져있다. 따라서, View 단을 렌더링 하면서 쿼리가 나갈 수 있다고 WARN을 띄워주는데 이를 없애려면 명시적으로 OSIV 기능을 설정하면 된다.
- 영속성 컨택스트를 요청이 들어올 때 미리 만들고, 응답할 때까지 유지시켜준다.
- 서블릿의 필터 혹은 스프링의 인터셉터에서 미리 영속성 컨택스트를 만들어서 사용한다.
- OSIV 덕분에 영속성 컨택스트가 살아있어서 Lazy Loading이 가능하다.
- 이로 인해 Service에 초기화를 위한 코드를 작성하지 않아도 된다.
영속성 컨택스트는 엔티티를 영구 저장하는 환경이다.
영속성 컨택스트는 트랜잭션이 시작될 때 만들어지고 트랜잭션이 커밋된 이후 없어진다.
즉시 로딩이란 객체 A를 조회할 때 A와 연관된 객체들을 한 번에 가져오는 것이고
지연 로딩이란 객체 A를 조회할 때는 A만 가져오고 연관된 애들은 프록시 초기화 방법으로 가져오는 것이다.
# OSIV의 필요성, 단점
OSIV는 왜 나오게 되었을까? 아래를 한 번 살펴보자.
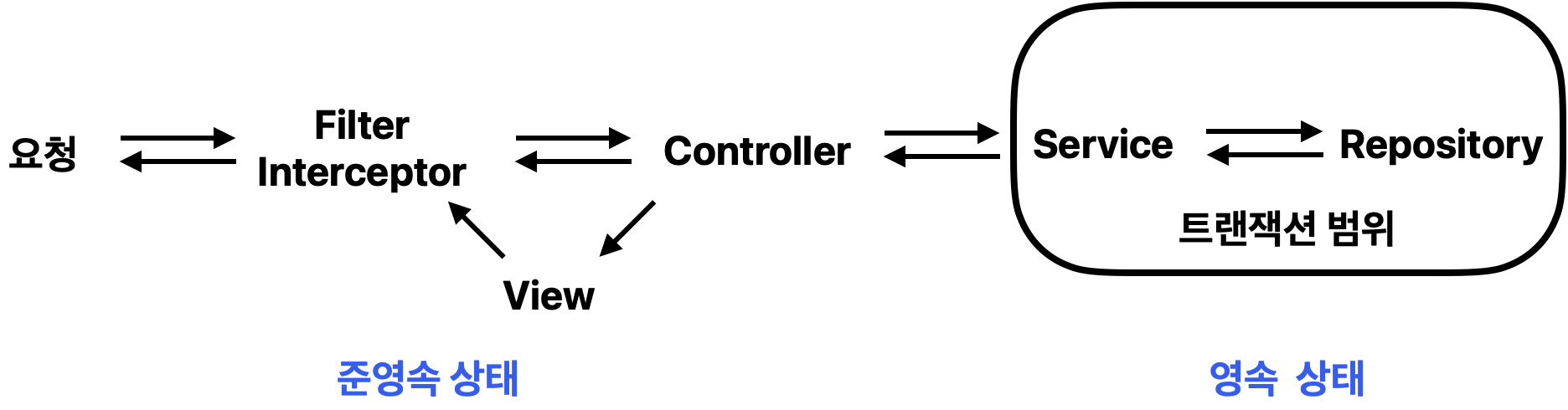
- 서비스에서 트랜잭션이 시작되면서 영속성 컨택스트가 만들어져 엔티티는 영속 상태가 되고, 서비스가 끝나면 트랜잭션도 끝나고 밖으로 나오면서 준영속 상태가 된다.
- 그런데, 만약 Post와 User가 다대일 연관관계로 매핑이 되어있는 경우에 Post entity를 Controller까지 가져와서 PostDto로 변환하려고 하면 어떻게 될까?
- Service가 끝났으니까 트랜잭션 종료되면서 영속성 컨택스트도 사라짐
- Controller까지 끌고온 Post는 다대일 연관관계라서 Lazy Loading을 시도했을 것
- 그런데 컨트롤러에 트랜잭션이 있을까? 없다. 따라서 영속성 컨택스트도 없다. 그래서
could not initialize proxy오류를 뱉을 것이다.
이런 이유로 트랜잭션 외부에서도 영속성 컨택스트가 존재하여 DB 커넥션을 유지하고, 영속성 컨택스트를 사용할 수 있는 기능의 필요성을 느끼게 된 것이다.
그러나, 이러한 특성으로 인해 OSIV에는 단점이 있다.
- 같은 영속성 컨택스트를 여러 트랜잭션이 공유할 수 있다.
- Presentation Layer에서 엔티티를 수정하고 Service Layer의 트랜잭션으로 들어오면 엔티티가 수정된다.
- Presentation Layer에서 Lazy Loading에 의한 SQL이 실행되기 때문에 성능 튜닝 시 확인해야할 부분이 Presentation Layer까지 넓어진다.
- DB 커넥션 시작 시점부터 응답이 나갈 때까지 DB 커넥션을 유지하는거라서 커넥션이 부족할 수 있다.
# JPA
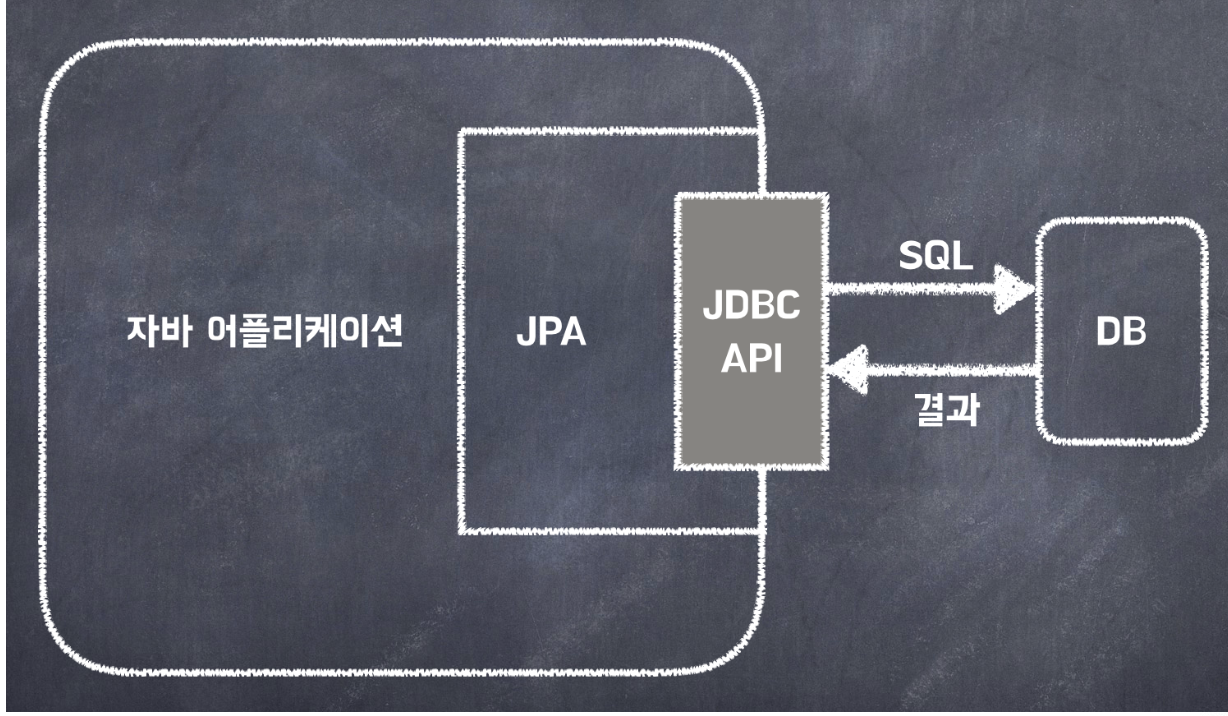
JPA(Java Persistence API)는 RDBMS와 OOP 객체 사이의 불일치에서 오는 패러다임을 해결하기 위해 자바 진영에서 만들어낸 ORM(Object-Relational Mapping) 기술의 표준 명세이다.
- Java에서 제공하는 API이다. Spring에서 제공하는 것이 아니다.
- 6주차 스터디에서 언급한 것처럼, Spring Framework의 PSA(Portable Service Abstraction)에 의해 POJO를 사용하면서 특정 기술인 ORM을 사용하기 위해 정해둔 표준 인터페이스이다.
- SQL을 매핑하지 않고 자바 클래스와 DB 테이블을 매핑
- 객체가 테이블이 되도록 매핑시켜주는 것
# 질문내용
# OSIV
OSIV란?
- 영속성 컨텍스트를 뷰까지 열어두는 기능
OSIV의 특징
- 클라이언트 요청이 들어올 때 영속성 컨텍스트를 생성해서 요청이 끝날 때까지 영속성 컨텍스트를 유지 → 뷰에서도 지연 로딩을 사용할 수 있음
- 트랜잭션 없이 읽기(Nontransactional reads)
- 트랜잭션이 없는 프레젠테이션 계층은 지연 로딩을 포함해 조회만 할 수 있다.
- 수정은 트랜잭션이 있는 계층에서만 동작한다.
- spring.jpa.open-in-view: true가 기본 값
OSIV가 켜져있는 경우 장단점
- 장점
- 데이터베이스 커넥션을 유지해서 지연 로딩이 가능하다.
- 단점
- 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자를 수 있다. → 장애 유발
- ex) 컨트롤러에서 외부 API를 호출하면 외부 API 대기 시간 만큼 커넥션 리소스를 반환하지 못하고, 유지해야 한다.
- 장점
OSIV가 꺼져있는 경우 장단점
- 장점
- 커넥션 리소스를 낭비하지 않는다.
- 단점
- 모든 지연 로딩을 트랜잭션 안에서 처리해야 한다.
- view, controller에서 지연로딩을 사용한 경우 모두 트랜잭션 안으로 넣어야 한다.
- 장점
OSIV의 동작 순서
- 클라이언트의 요청이 들어오면 서블릿 필터나, 스프링 인터셉터에서 영속성 컨텍스트를 생성한다. 단 이 시점에서 트랜잭션은 시작하지 않는다.
- 서비스 계층에서
@Transactional로 트랜잭션을 시작할 때 1번에서 미리 생성해둔 영속성 컨텍스트를 찾아와서 트랜잭션을 시작한다. - 서비스 계층이 끝나면 트랜잭션을 커밋하고 영속성 컨텍스트를 플러시한다. 이 시점에 트랜잭션은 끝내지만 영속성 컨텍스트는 종료되지 않는다.
- 컨트롤러와 뷰까지 영속성 컨텍스트가 유지되므로 조회한 엔티티는 영속 상태를 유지한다.
- 서블릿 필터나, 스프링 인터셉터로 요청이 돌아오면 영속성 컨텍스트를 종료한다. 이때 플러시를 호출하지 않고 바로 종료한다.
현재 스프링 프레임워크가 제공하는 OSIV 트랜잭션 작동 범위
- 영속성 컨텍스트는 사용자의 요청 시점에서 생성이 되지만, 데이터를 쓰거나 수정할 수 있는 트랜잭션은 비즈니스 계층에서만 사용할 수 있도록 트랜잭션이 일어난다.
트랜잭션 범위 밖에서 엔티티 수정할 경우 수정 사항이 DB에 반영될까요?
- 스프링이 제공하는 OSIV는 요청이 끝나면 플러시를 호출하지 않고 em.close()로 영속성 컨텍스트만 종료한다. 따라서 반영되지 않는다.
그렇다면 프레젠테이션 계층에서 em.flush()를 호출하더라도 데이터가 수정되지 않나요?
- 프레젠테이션 계층에서 em.flush()를 호출하여 강제로 플러시해도 트랜잭션 범위 밖이므로 데이터를 수정할 수 없다는 예외가 발생한다.(javax.persistence.TransactionRequiredException)
OSIV 사용시 주의사항
- 자원
- OSIV의 전략은 트랜잭션 시작처럼 최초 데이터베이스 커넥션 시작 시점부터 API 응답이 끝날 때까지 영속성 컨텍스트와 데이터베이스 커넥션을 유지한다. 그래서 View Template이나 API 컨트롤러에서 지연 로딩이 가능하다.
- 지연 로딩은 영속성 컨텍스트가 살아있어야 가능하고, 영속성 컨텍스트는 기본적으로 데이터베이스 커넥션을 유지한다. 이것 자체가 큰 장점이다.
- 하지만 이 전략은 오래동안 데이터베이스 커넥션 리소스를 사용하기 때문에, 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자랄 수 있다. 이것은 결국 장애로 이어진다.
- 예를 들어서 컨트롤러에서 외부 API를 호출하면 외부 API 대기 시간 만큼 커넥션 리소스를 반환하지 못하고, 유지해야 한다.
- → 영속성 컨텍스트가 종료될 때까지 DB Connection을 유지하므로, Connection 자원 소모가 크다.
- 자원
엔티티가 수정되고 트랜택션이 있는 비즈니스 로직이 호출되면 수정 사항이 DB에 반영될까요?
- 같은 영속성 컨텍스트를 여러 트랜잭션이 공유할 수 있으므로 수정이 발생한다.하지만 보통 컨트롤러는 비즈니스 로직을 먼저 호출하고 그 결과를 조회하므로 이런 문제는 거의 발생하지 않는다.
# JPA
JPA란?
- 자바 진영의 ORM 기술 표준 인터페이스
JPA를 사용하는 이유?
- SQL 중심적인 개발에서 객체 중심의 개발
- 1차 캐시와 동일성 보장
- 같은 트랜젝션 안에서는 같은 엔티티를 반환 - 약간의 조회 성능 향상
- 따라서 같은 instance로 판단된다.
- 트랜젝션을 지원하는 쓰기 지원
- 트랜잭션을 커밋할 때까지 insert sql 모은다
- JDBC BATCH SQL 기능을 사용해서 한 번에 SQL 전송
- 지연 로딩 사용 가능
- 유지 보수
- 데이터 접근 추상화와 벤더 독립성
- 특정 데이터베이스 기술에 종속되지 않음
- 변화에 유연하게 대응 가능
- 엔티티로 관리되므로 스키마 변경시 엔티티만 수정하게 되면 엔티티를 사용하는 관련 쿼리는 자동으로 변경된 내역이 반영된다.
- 객체지향적으로 데이터를 관리할 수 있다.
JPA의 단점에는 무엇이 있을까요?
- 러닝 커브 존재
- 통계 처리와 같은 복잡한 쿼리 처리 어려움
- Native Query, JPQL, queryDsl 등을 사용하여 해결
- 성능
- 객체 간의 올바른 매핑 설계가 이뤄지지 않으면 성능 저하 발생 가능
- 자동으로 생성되는 쿼리가 많기 때문에, 개발자가 의도하지 않은 쿼리로 성능이 저하 발생 가능
- N + 1 문제
- FetchType
- FetchJoin
- Proxy
JPA의 단점을 보완하는 방법에는 무엇이 있을까요? -> 3번 참조
# N+1문제
N+1문제란?
- 요청이 1개의 쿼리로 처리되길 기대했는데 N개의 추가 쿼리가 발생하는 현상
N+1문제가 발생하는 이유
- JPA Repository로 find 시 실행하는 첫 쿼리에서 하위 엔티티까지 한 번에 가져오지 않고, 하위 엔티티를 사용할 때 추가로 조회하기 때문이다.
- JPQL은 기본적으로 글로벌 Fetch 전략을 무시하고 JPQL만 가지고 SQL을 생성하기 때문이다
즉시 로딩, 지연 로딩이란?
- 즉시로딩: 특정 엔티티를 조회할 때 연관된 모든 엔티티를 같이 로딩하는 것
- 지연 로딩: 필요한 시점에 연관된 객체의 데이터를 불러오는 것
즉시 로딩, 지연 로딩에서 N+1 문제가 발생하는 과정
EAGER(즉시 로딩)인 경우
JPQL에서 만든 SQL을 통해 데이터를 조회
이후 JPA에서 Fetch 전략을 가지고 해당 데이터의 연관 관계인 하위 엔티티들을 추가 조회
2번 과정으로 N + 1 문제 발생
LAZY(지연 로딩)인 경우
JPQL에서 만든 SQL을 통해 데이터를 조회
JPA에서 Fetch 전략을 가지지만, 지연 로딩이기 때문에 추가 조회는 하지 않음
하지만, 하위 엔티티를 가지고 작업하게 되면 추가 조회가 발생하기 때문에 결국 N + 1 문제 발생
N+1문제 해결법
fetch Join
- JPQL을 사용하여 DB에서 데이터를 가져올 때 처음부터 연관된 데이터까지 같이 가져오게 하는 방법이다. (SQL Join 문을 생각하면 된다. )
@EntityGraph
@EntityGraph의attributePaths에 쿼리 수행 시 바로 가져올 필드 명을 지정하면 Lazy가 아닌 Eager 조회로 가져오게 됩니다.
Batch Size
이 옵션은 정확히는 N+1 문제를 안 일어나게 하는 방법은 아니고 N+1 문제가 발생하더라도 select * from user where team_id = ? 이 아닌 select * from user where team_id in (?, ?, ? ) 방식으로 N+1 문제가 발생하게 하는 방법이다.
이렇게 하면 100번 일어날 N+1 문제를 1번만 더 조회하는 방식으로 성능을 최적화할 수 있다.
단 Batch Size의 한계값은 1000 정도
# fetch join 한계 - OneToMany fetch join 페이징 쿼리 성능 이슈
발생 이유
- JPA에서 @ToMany 관계에 대해 Paging + fetch join을 수행할 때, One Entity 기준으로 Many Entity에 대한 데이터를 join하게 되어 데이터의 수가 변한다.
- ex) Review 2개, Image 3개일 때 row는 총 6개가 생김.
(2 != 6) - 따라서 JPA는 어떤 데이터를 기준으로 Paging을 수행해야 하는 지 알 수 없게 된다.
해결 방법
- 중복 데이터
- → JPQL에서 지원하는 distinct를 사용하여 해결
- 같은 식별자를 가진 엔티티 중복 제거
xToMany에서 페이징이 불가능하다.- limit 쓰면 OOM(Out of Memory) 발생
- 데이터를 전부 가져오고나서 메모리에서 페이징을 하기 때문
- limit 쓰면 OOM(Out of Memory) 발생
- → 지연로딩으로 조회,
@BatchSize적용 - → N의 테이블의 기준으로 fetchJoin하여 findAll로 Paging + 합치기
- 중복 데이터
# fetch join 한계 - MultipleBagFetchException
어떨 때 발생하는 exception?
- 2개 이상의 OneToMany 자식 테이블에 Fetch Join을 사용했을 때 발생
이러한 fetch join 문제들 해결하는 방법?
hibernate.default_batch_fetch_size를 글로벌 설정으로 사용해 N+1 문제를 최대한in쿼리로 기본적인 성능을 보장하게 한다.- 한계값 1000 존재
@OneToOne,@ManyToOne과 같이 1 관계의 자식 엔티티에 대해서는 모두 Fetch Join을 적용하여 한방 쿼리를 수행한다.@OneToMany,@ManyToMany와 같이 N 관계의 자식 엔티티에 관해서는 가장 데이터가 많은 자식쪽에 Fetch Join을 사용한다.- Fetch Join이 없는 자식 엔티티에 관해서는 위에서 선언한
hibernate.default_batch_fetch_size적용으로 100~1000개의in쿼리로 성능을 보장한다.
- Fetch Join이 없는 자식 엔티티에 관해서는 위에서 선언한
# OneToOne 양방향 관계 Lazy 로딩 문제
OneToOne 양방향 관계 Lazy Loading 문제가 무엇인가요?
- 외래키를 가지고 있는 주인 테이블을 조회할 때는 지연 로딩이 동작하지만, mappedBy 속성으로 연결된 외래키를 가지지 않은 쪽에서 테이블을 조회할 경우 지연 로딩이 동작하지 않고 N+1 문제가 발생하는 것
발생 이유?
- 외래키를 가지지 않은 테이블에서는 주인 테이블 객체가 null 인지 아닌지를 조회해보기 전까지는 알 수 없습니다. LAZY 로딩으로 설정이 되어있는 엔티티를 조회할 때는 프록시로 감싸서 동작하게 되는데, 프록시는 null을 감쌀 수 없기 때문에 지연 로딩으로 설정하여도 즉시 로딩이 수행되게 되는 문제가 발생합니다.
해결 방안
- 구조 변경하기
- 양방향 매핑이 반드시 필요한 상황인지 다시한번 생각해본다.
- OneToOne -> OneToMany 또는 ManyToOne 관계로 변경이 가능한지 생각해본다.
- 구조를 유지한채 해결하기
- CART를 조회할때 USER도 함께 조회한다. (Fetch Join)
- batch fetch size를 사용한다.
- 외래키가 어디있냐에 따라 장단점이 있다.
- 주 테이블에 두는 경우는 주 테이블만 확인해도 대상 테이블과의 연관관계를 확인할 수 있다.
- 반면에 대상 테이블에 두는 경우는 일대다로의 확장이 좋다는 장점이 있지만 양방향 매핑을 무조건 해야한다는 단점이 있다.
- 구조 변경하기
# @OneToMany는 괜찮나?
- 양방향일 때 외래키를 관리하는 쪽(연관관계의 주인)은 다 쪽이다.
- 일(One)쪽에는 다의 존재를 알 수 있는 방법이 없다.
- 그러면 마찬가지로 Lazy loading을 못할까? 그렇지 않다.
- 이유는 컬렉션이다. 컬렉션이기에 null을 표현할 방법이 있다.
- 무조건 프록시 객체를 만들어놓고 막상 조회해보니 없어 미안! 하고 빈 컬렉션을 리턴하면 표현이 가능하다! (null을 리턴하지 않고 null과 같이 연관 관계가 없음을 표현할 size=0이 있기 때문이다.
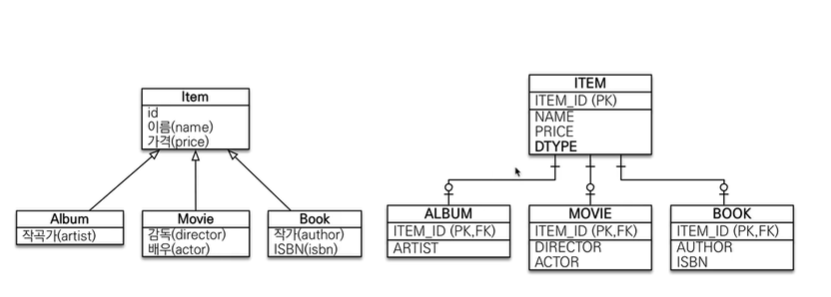
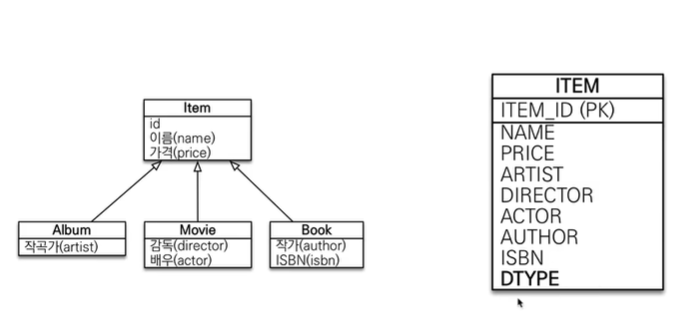
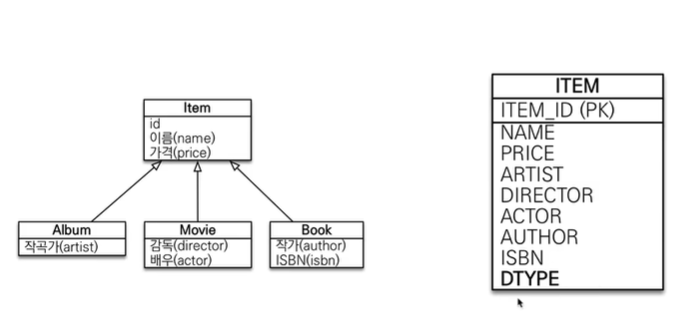
# 상속관계 매핑
상속관계 매핑이 무엇인가요?
- 객체의 상속 구조와 DB의 슈퍼타입 서브타입 관계를 매핑하는 것
상속관계 매핑의 목적이 무엇인가요?
- 객체는 상속관계가 존재하지만, 관계형 데이터베이스는 상속 관계가 없다.
- 이러한 OOP와 ORM의 패러다임 불일치를 해결하기 위해 다양한 전략이 사용된다.
방법 3가지?
- 조인 전략, 단일 테이블 전략. 구현 클래스마다 테이블 전략
각각 장단점?
조인 전략
장점
- 테이블 정규화
- 외래 키 참조 무결성 제약조건 활용 가능
- 저장공간 효율
단점
- 조회 시 조인을 많이 사용, 성능 저하
- 조회 쿼리 복잡함
- 데이터 저장 시 INSERT SQL 2번 호출
- 단일 테이블에 비해 복잡하다.
단일 테이블 전략
장점
- 조인이 필요 없으므로 조회 성능이 빠르다
- 조회 쿼리가 단순하다
단점
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있는 상황에 따라서 조회 성능이 오히려 느려질 수도 있다.
구현 클래스마다 테이블 전략
장점
- 서브타입을 명확하게 구분해서 처리할 때 효과적
- NOT NULL 제약조건 사용 가능
단점
- 여러 자식 테이블이 함께 조회할 때 성능이 느림
- 자식 테이블을 통합해서 쿼리하기 어려움
⇒ 추천 X
# 선학님 질문
fetch Join 과 join의 차이점은 뭘까요?
- 답 : fetch Join = 조회하는 쿼리에서 단일 게시물이 갖고 있는 데이터를 하나의 쿼리문으로 조회
- Join = 조회하는 쿼리에서 단일 게시물이 갖고있는 pk값만 조회 후 조회 쿼리 N번 수행 (FetchType.EAGER) 일시, 즉 fetch Join은 조회 주체 엔티티와 연관 관계 엔티티, 2개의 엔티티 모두 영속성 컨텍스트로 관리
- 일반 Join은 조회 주체가 되는 엔티티만 조회하고 영속화
OSIV에 단점을 설명해 주시고 이러한 단점이 있는데 실무에서 사용을 할까요?
- 답 : 실무에서 관리자 즉 Admin Application에서는 OSIV를 true로 사용하고 실시간 트래픽이 중요한 Application에서는 성능이 더 중요하기 때문에 false로 설정합니다. (대규모 서비스에 예제)
- 소규모 서비스는 보통 true로 설정하고 진행
One-To-One 관계에서 Lazy 로딩이 특정 조건에서 사용되는데 어디쪽에서 동작을 할까요?
- 답 : 연관관계 주인 Entity 측에서 Lazy 로딩이 작동
그렇다면 3번 문제에서 Lazy로딩이 연관관계 주인쪽에서만 동작한다고 했는데 이를 해결하는 방법은 뭐가 있을까요?
- 답 : fetch Join을 활용해야한다.
fetch Join을 활용했을때에 단점은 뭐가 있을까요?
- 답: 연관관계 주인 테이블이 무거워지는 단점이 있습니다.
그렇다면 실무에서는 어떤게 더 좋은 방향일까요?
- 답: 실제 상황에 따라 트레이드 오프를 고려해서 선택하면 됩니다.
JPA 사용 시 성능 저하 위험이 있는데 이는 어떤 위험도를 가지고 있을까요?
- 답 : 객체 간의 맵핑 설계를 잘못했을 때 성능저하 + 자동으로 생성되는 쿼리가 개발자가 의도하지 않는 쿼리로 인해 성능이 저하됩니다.
연관관계를 사용하면 FK를 걸어줘야하는데 실무에서는 사용할까요?
- 답 : 회사 By 회사
- 이유는 : FK 자체가 데이터베이스를 샤딩하는 데 방해가 되고 FK가 성능에 영향을 미칠 수도 있습니다. 이런거 때문에 대규모 프로젝트를 할때는 연관관계를 걸지 않습니다. 그냥 @Column으로 정의해주고 JPQL 혹은 QueryDSL로 조인을 걸어서 사용합니다.