7주차 - Spring 트랜잭션
7주차 스터디
TOPIC
- DataSource
- Connection Pool
- 데이터베이스 트랜잭션
- 트랜잭션 동기화
- 트랜잭션 추상화
- Spring 트랜잭션
# DataSource
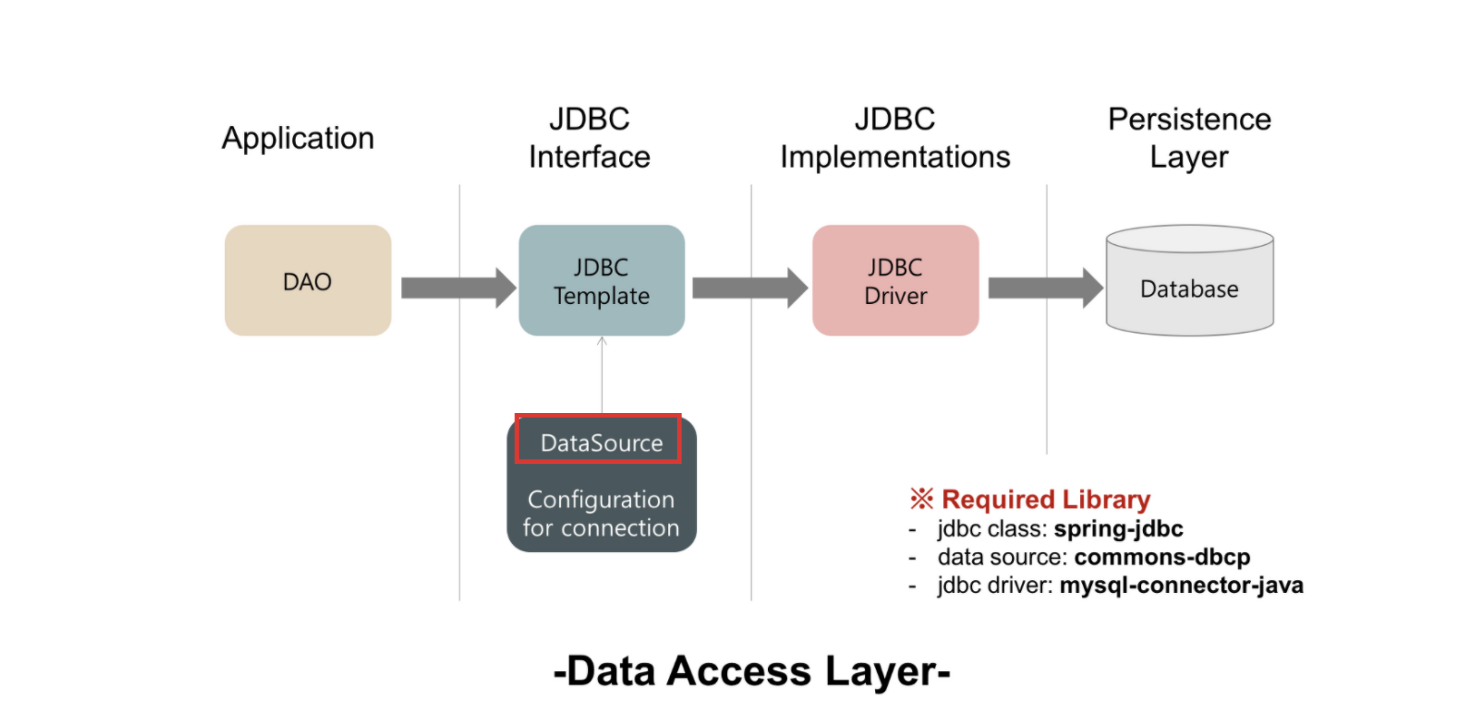
DataSource는 물리적인 데이터베이스에 연결하기 위한 팩토리이다.
- DataSource 인터페이스는 JDBC API에 있고, DataSource가 DB에 연결하기 위해 드라이버이름/아이디/비밀번호/URL을 사용한다.
- 커넥션 관련 기술은 다양하여 코드가 다 다르기 때문에, 커넥션을 획득하는 역할을 추상화시킨 DataSource가 등장한 것이다.
- 실질적인 커넥션 로직은 DataSource에 의존하도록 하면 구현 기술이 바뀔때마다 DataSource의 구현체만 바꾸면 되기 때문이다.
다양한 커넥션 관련 기술은 아래와 같다.
- DriverManager : DriverManager 클래스는
Class.forName()메서드를 통해서 생성되는데, 인터페이스 드라이버를 구현하는 작업을 한다. 특정 클래스를 로딩하면 자동으로 객체가 생성되고 DriverManager에 등록된다. 특징적으로는 사용자가 요청할 때마다 드라이버를 로드하고 커넥션 객체를 생성하여 연결하고 종료한다는 점이다. 또, 따로 DataSource를 구현하지 않기 때문에 Spring에서 DriverManagerDataSource라는 구현 클래스를 제공한다.- 매번 커넥션을 생성하기 때문에 전체적인 리소스 낭비가 심하다.
- 이 단점을 보완하기 위한 것이 커넥션 풀, DBCP(DataBase Connection Pool)이다.
- Connection Pool 이용 (아래에서 설명)
# Connection Pool
DataBase Connection Pool(DBCP, 커넥션 풀)은 웹 컨테이너(WAS)가 실행되면서 일정량의 Connection 객체를 미리 만들어서 pool에 저장했다가 클라이언트 요청이 오면 Connection 객체를 빌려주고 해당 객체의 임무가 끝나면 다시 Connection 객체를 반납 받아서 pool에 저장하는 방법이다.
요청이 적은 경우에는 상관없지만, 요청이 많은 경우 매번 커넥션을 생성하는 것은 리소스 낭비가 심해서 나오게 된 방법이다. 대표적인 커넥션 풀의 시로는 아래와 같다.
- commons-dbcp
- 아파치에서 제공하는 라이브러리
- tomcat-jdbc-pool
- tomcat에 내장되어 있고 Apache Commons DBCP 라이브러리를 바탕으로 만들어져있다.
- Spring Boot 2.0.0 하위 버전의 default DBCP이다.
- HikariCP
- Spring Boot 2.0.0 부터 default JDBC Connection Pool이다.
- Connection Pool을 제공하는 JDBC DataSource의 구현체이다.
- tomcat-jdbc-pool과 비교해 벤치마크 성능이 잘 나온다.
- 이는 zero-overhead의 특징 때문이다.
- overhead : 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 및 메모리
# DBCP의 과정
- WAS가 실행되면서 Pool 내에 Connection 객체들을 미리 생성해둔다. (default : 10)
- HTTP의 요청이 올 때 Pool 내에서 Connection 객체를 가져가서 사용
- 사용이 완료된 Connection 객체는 Pool 내에 반환
스프링부트 2.0 이후의 default Connection Pool인 HikariCP의 동작 원리도 살펴보자.
Thread가 Connection을 요청하면 Connection Pool이 유휴 Connection 객체를 찾아서 반환한다. HikariCP는 이전에 사용했던 Connection이 존재하는지 확인하고 이를 우선적으로 반환하는 특징이 있다.
- Connection 요청 들어옴
- Connection pool이 이전 사용했던 Connection이 존재하는지 확인
- 이전 사용했던 Connection 목록 중 사용 가능한 Connection 존재하는지 확인
- 전체 Connection 목록 중 사용 가능한 Connection 존재하는지 확인
- 2, 3, 4 과정은 순서대로 실행되며, 사용 가능한 커넥션이 존재하면 다음 과정 생략 후 반환
- Connection 반환
가능한 Connection이 없으면 HandOffQueue를 Polling (상태를 주기적으로 검사하여 일정한 조건을 만족하면 송수신 등의 자료처리를 하는 방식) 하면서 다른 Thread가 Connection을 반납하기를 기다린다.
- 지정된 TimeOut 시간까지 대기하다가 시간이 만료되면 예외를 던짐
최종적으로 Connection을 반납하면 Connection Pool이 사용 내역을 기록하고 HandOffQueue에 반납된 Connection을 삽입
- HandOffQueue Polling 하던 Thread는 Connection을 얻고 작업 시작
# DBCP 특징/고려사항
DBCP 장점
- Connection 객체를 미리 만들어 연결하여 메모리 상에 등록해 놓기 때문에 불필요한 작업(커넥션 생성, 삭제)이 사라지므로 클라이언트가 빠르게 DB에 접속이 가능하다.
- DB 접속 모듈을 공통화하여 DB 서버의 환경이 바뀔 경우 쉬운 유지 보수가 가능하다.
- 연결이 끝난 Connection을 재사용함으로써 새로 객체를 만드는 비용을 줄일 수 있다.
- Connection 수를 제한할 수 있어서 과도한 접속으로 인한 서버 자원 고갈 방지가 가능하다.
DBCP 고려사항
- Connection 수가 제한되어 있어서 동시 접속자가 많으면 Connection 반납까지 대기해야함
- Connection Pool을 크게 설정 -> 메모리 소모 커짐, 대신 많은 사람의 대기시간 감소
- Connection Pool을 작게 설정 -> 메모리 소모 감소, 대신 많은 사람의 대기시간 증가
- Connection을 사용하는 주체가 Thread 임으로 함께 고려해야 한다.
Thread Pool 크기 < Connection Pool 크기- Thread Pool에서 트랜잭션을 처리하는 Thread가 사용하는 Connection 외에 남는 Connection은 실질적으로 메모리 공간만 차지함
Thread Pool 크기, Connection Pool 크기 모두 증가- Thread Pool이 커지면서 Thread 수가 늘어나 더 많은 Context Switching 발생
- 오버헤드가 더 많이 발생
- Disk 경합 측면에서 성능 한계 발생
- DB는 하드디스크 하나 당 하나의 I/O를 처리하므로 블로킹이 발생한다.
- 즉, 특정 시점부터는 성능적인 증가가 Disk 병목으로 인해 미비해짐
- Thread Pool이 커지면서 Thread 수가 늘어나 더 많은 Context Switching 발생
Context Switching? 블로킹?
컨택스트 스위칭(Context Switching) 은 프로세스나 스레드의 상태를 저장하고, 나중에 해당 상태를 복원하여 실행을 재개하고, 이전에 저장한 다른 상태를 복원하는 과정을 의미한다. 이를 통해 여러 프로세스가 하나의 중앙 처리 장치(CPU)를 공유할 수 있으며, 멀티태스킹 운영 체제의 필수 기능이다.
블로킹은 호출된 함수나 작업이 완료될 때까지 대기하며, 논블로킹은 비동기적으로 작업을 처리하며, 호출된 함수나 작업이 완료되지 않아도 다음 코드를 실행하는 것을 의미한다. 입출력(I/O)에서도 블로킹과 논블로킹이 중요한데 블로킹 I/O는 데이터가 준비될 때까지 대기하며, 논블로킹 I/O는 즉시 반환하는 것이다. 그러나 논블로킹 I/O는 즉시 반환된다고 해서 항상 데이터를 반환하는 것은 아니기도 하다.
# 데이터베이스 트랜잭션
Transaction은 정보 교환과 관련된 작업에서 일련의 순서를 나타내고 요청을 충족시키기 위해 데이터 무결성을 보장하기 위해 여러 개의 작업을 하나로 작업으로 묶은 작업 단위이다. 메시지 큐 트랜잭션 같은 것도 있지만, 보통 말하는 것이 DB 트랜잭션을 의미한다. DB 트랜잭션은 데이터베이스의 상태를 변경시키는 작업의 단위이다.
# 트랜잭션 성질
트랜잭션이기 위해서는 ACID라는 4가지 성질을 만족해야 한다. 이 중 가장 중요한 성질은 원자성!! 애초에 여러 작업을 하나의 트랜잭션 단위로 묶는데, 이 원자성이 깨져버리면 나머지 속성이 의미가 없는 것이다.
원자성(Atomicity)
- 트랜잭션에 속한 각각의 쿼리(읽기, 쓰기, 업데이트, 삭제)를 하나의 단위로 취급
- 트랜잭션의 연산이 모두 성공하거나, 모두 실패하는 성질
- 전체를 실행하거나 어떤 부분도 실행하지 않거나 둘 중 하나이다. 애매하게 실행하다가 끝 이런건 없다.
일관성(Consistency)
- 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효하여, DB 상태가 일관되어야 하는 성질
- 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야 한다는 의미
격리성(Isolation)
- 여러 사용자가 같은 테이블에서 동시에 읽고 쓰는 작업을 할 때, 각각의 트랜잭션을 경리하여 동시 트랜잭션이 서로 방해하거나 영향을 끼치지 않도록 하는 것
- 실제로 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜잭션은 고립(격리)되어 있어서 연속으로 실행된 것과 동일한 결과를 나타냄
지속성(Durability)
- 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야하는 성질
- 런타임 오류나 시스템 오류가 발생하더라도, 해당 기록은 영구적이어야 한다는 뜻
# JDBC api 트랜잭션
JDBC API를 이용하여 개발하는 상황이라고 하자. 예를 들어, 체스 말을 움직이는 메서드를 비즈니스 로직에서 사용하는데, move 메서드는 한 칸씩 이동하는 메서드라 두 번 움직이게 하려고 메서드를 두 번 사용했다고 하자.
- 두 번의 update 쿼리를 날림. 각 update는 새로운 트랜잭션 생성하여 DB에 저장
- 각 쿼리마다 DB에 트랜잭션을 커밋함. 첫 번째 쿼리 정상 커밋 -> RuntimeException -> 두 번째 쿼리는 빈 값을 커밋 -> DB에 정보 어디감!? 이렇게 된다.
이를 해결하기 위해 하나의 비즈니스 로직은 단일(같은) 트랜잭션으로 관리하기로 했다.
- 서비스 단의 비즈니스 로직 시작 전에 트랜잭션을 시작하고 비즈니스 로직 끝난 후에 트랜잭션을 끝내야함
- 이를 트랜잭션 경계를 설정했다고 한다.
대신, 이렇게 하면 단점이 있다.
- Service 코드가 복잡해진다.
- Connection 유지를 어떻게 할 것인가?
- 데이터 액세스 기술에 의존적인 코드를 작성한다.
- 예를 들어, JDBC가 아닌 JPA를 사용하겠다고 하면 다바꿔야한다.
- 트랜잭션을 중복해서 사용할 일도 있을 것,
- 비즈니스 로직과는 다른 관심사의 일을 수행한다.
- DB 연결은 비즈니스 로직과 관심사가 다르니까
# Spring 트랜잭션
JDBC API 트랜잭션에서 언급했던 단점을 Spring Framework를 사용하면서 깔끔하게 해결해준다.
트랜잭션 동기화
- 순수 JDBC는 커넥션 유지를 위해 Connection 객체를 계속 메서드의 파라미터로 넣었다.
- 이를 해결하기 위해 스프링에서는 현재 스레드에 대한 트랜잭션 동기화를 활성한다.
- TransactionSynchronizationManager
트랜잭션 추상화
- 데이터 액세스 기술과 트랜잭션, 서비스 사이의 종속성(dependency) 제거
- 트랜잭션 기능을 쉽게 활용해주도록
선언적 트랜잭션
- 비즈니스 로직과 트랜잭션 관련 로직을 완전히 분리해줌
# 트랜잭션 동기화
JDBC를 이용하면서 여러 개의 작업을 하나의 트랜잭션으로 관리할 때 Connection 객체를 유지해야해서 얻는 불편함이 발생했었다. Spring Framework에서 제공하는 트랜잭션 동기화 기술은 어떤 방식으로 해결할까?
트랜잭션을 시작하기 위한 Connection 객체를 특별한 저장소에 보관해 두고 필요할 때 꺼내 쓰는 방식으로 기술을 제공한다. 이 특별한 저장소를 트랜잭션 동기화 매니저라고 한다.
- 트랜잭션 동기화 매니저는 스레므다마 Connection 객체를 독립적으로 관리하므로, 멀티 스레드 환경에서 충돌이 발생하지 않는다.
- 따라서, 트랜잭션 동기화 매니저는 Thread-safe하다.
트랜잭션 동기화 매니저 동작 과정
- 서비스에서 트랜잭션이 시작하면 트랜잭션 동기화 매니저가 커넥션을 생성하고 autoCommit을 false로 세팅한 이후 트랜잭션 동기화 매니저의 thread 로컬에 커넥션을 보관
- 커넥션 풀을 사용하면 커넥션 풀에서 커넥션 가져옴
- 리포지토리 레이어에서 트랜잭션 동기화 매니저의 스레드 로컬에서 해당 커넥션을 가져와서 사용
- 서비스에서 트랜잭션을 종료할 때는 트랜잭션 동기화 매니저에서 해당 커넥션을 가져와서 commit 혹은 rollback을 수행하고 리소스를 정리 후 커넥션을 닫으면서 반환
- 커넥션 풀을 사용하면 커넥션 풀에 커넥션 반환
하지만, 만약에 JDBC가 아니라 Hibernate와 같은 기술을 사용한다면? 트랜잭션 동기화도 완벽하지 않다. -> 트랜잭션 동기화 코드가 JDBC에 종속적이기 때문이다. 왜냐하면, 데이터 접근 기술이 아래와 같이 다르기 때문이다.
- JDBC : Connection
- JPA : EntityManager
- Hibernate : Session
# 트랜잭션 추상화
JDBC, JPA, Hibernate가 하는 일은 모두 동일할 것이다.
- 트랜잭션을 가져오고 생성
- 해당 트랜잭션을 커밋
- 해당 트랜잭션을 롤백
구현 방식에 상관없이 동일한 임무를 수행하는 구현체이기 때문에 이에 대한 추상화가 가능하다. Spring Framework가 제공하는 트랜잭션 추상화 기술은 트랜잭션 관리 부분을 추상화한 기술을 의미한다. Spring은 PlatformTransactionManager 인터페이스를 생성해서 JDBC, JPA, Hibernate 각 구현체들이 트랜잭션을 가져오는 방식을 명세로 추상화 해두었다.
- 이로 인해, 애플리케이션은 각 구현체에 종속적인 코드를 이용하지 않으면서 일관되게 트랜잭션을 처리할 수 있게 되었다.
트랜잭션 추상화의 장점적인 부분은 많은 트랜잭션 기능을 제공해주는 것 이외에도 POJO에 가깝게 구현하여 테스트에 용이하다는 장점이 있다. 하지만 반대로, 추상화라는 것 자체가 코드 레벨이 깊어진다는 의미라 테스트가 용이하지 않게 되는 단점이 될 수도 있다.
# 선언적 vs 프로그래밍
스프링에서는 트랜잭션 처리를 2가지 방식으로 지원한다.
프로그래밍 방식 트랜잭션
- 위와 같이 PlatformTransactionManager나 TransactionTemplate을 직접 사용해서 프로그래밍 코드를 작성하는 방식
- Spring docs에서는 TransactionTemplate을 사용하는 것을 권장
- 트랜잭션 로직을 직접 하드코딩으로 관리 가능
- 트랜잭션의 시작, 종료 시점을 명시적으로 결정하여 트랜잭션 경계를 개발자가 설정하도록
- 트랜잭션의 유연한 관리 가능
- 다수의 트랜잭션 관리하기에 힘들다
- 적은 양의 트랜잭션이 사용될 때 사용하는 것을 권장
선언적 트랜잭션
@Transactional애노테이션을 사용한 트랜잭션 관리 방식- Spring AOP를 통해 구현되어지는 방색
- 트랜잭션 로직과 비즈니스 로직을 분리하여 관리 가능
- 유지보수 쉬움
- 다수의 트랜잭션 관리할 때 선호
- AOP로 구현되므로, 내부 메서드 transaction으로는 사용 불가능
프로그램상에 트랜잭션이 적을 때는 트랜잭션 프록시를 설정하지 않을수 있기 때문에 TransactionTemplate을 이용하는 것이 좋다고 하고, 다수의 트랜잭션 작업이 있는 경우 트랜잭션 관리를 비즈니스 로직에서 제외시키고 구성할수 있기 때문에 유지보수에 편리할 수 있다고 한다.
# AOP 이용 트랜잭션 분리
JDBC를 이용하여 여러 작업을 단일 트랜잭션으로 관리하게 되었다. 하지만, 코드가 매우 복잡해지고 Connection 객체 유지를 위해 메서드에 불편하게 넣어야했다. 이를 해결하기 위해 Spring에서 제공하는 트랜잭션 동기화 기술은 트랜잭션 동기화 매니저를 통해 Connection 객체를 관리하게 되었고, 데이터베이스 접근 기술에 의존적이던 부분은 트랜잭션 추상화 기술을 통해 해결했다. 마지막으로 남은 문제가 서비스의 비즈니스 로직과는 관심사가 다른 부분이다.
위에서도 잠깐 언급했지만 선언적 트랜잭션 방식인 @Transactional 애노테이션을 활용해 이를 해결한다.
- 트랜잭션 로직을 클래스 밖으로 빼내서 별도의 모듈로 만드는 AOP를 고안하였었다.
- 이를 적용한 것이 트랜잭션 애노테이션이다.
@Transactional을 사용하면 감싸는 프록시를 사용하기 때문에 추가적인 코드를 작성할 필요 없이 간편하게 사용할 수 있다.
# @Transactional
@Transactional 애노테이션은 AOP로 구성되어있다고 했다.
- 클래스, 메서드 위에 애노테이션 선언하면 트랜잭션 기능이 적용된 프록시 객체가 생성
- 클래스에 붙으면 클래스의 전체
public 메서드에 트랜잭션 처리가 된 프록시가 빈으로 등록 public, protected, default가 아닌 private 접근제한자가 붙은 메서드의 경우 트랜잭션 처리 되지 않음- 프록시가 메서드 오버라이딩 개념이라 public으로 열려있지 않고 private으로 닫혀있으면 안되는 거임
- 추가로, static, final이 붙어도
@Transactional이 작동하지 않는다. non-public이라서이다. 자세한 내용은 non-public methods should not be @transactional로 검색해보자.
- 클래스에 붙으면 클래스의 전체
- 프록시로 동작하므로 메서드 오버라이딩 개념으로 동작
- 요청이 오면 프록시 객체가 요청을 받고 프록시 객체에서 트랜잭션을 시작
- 적용하고자 하는 실제 객체의 메서드에서 invoke하여 사용하고 트랜잭션 커밋/롤백
@Transactional은 auto commit을 false로 하고 마지막에 커밋/롤백 한다.
# 선언적 트랜잭션 문제점
선언적 트랜잭션은 내부 호출 문제가 있다.
@Transactional을 사용한 메서드를 같은 객체 안에서 불러온다고 생각해보자.
- 선언적 트랜잭션은 프록시 객체이기 때문에 같은 내부에서 호출하면 트랜잭션이 정상 작동하지 않음
- 객체 변경 감지는 트랜잭션이 커밋될 때 작동하는데, Spring이
@Transactional을 선언한 메서드가 호출되기 전에 트랜잭션을 시작하는 코드를 삽입하고, 실행 이후에 commit 코드를 삽입하여 객체 변경 감지를 수행하도록 유도하기 때문이다.- Spring에서 이 방식으로 프록시 객체로 한 번 더 감싸기 때문에 프록시 객체가 제공하는 메서드를 사용해야만 트랜잭션이 수행된다.
핵심은 AOP 프록시를 씌우려면 타겟 메서드를 감싸야 한다는 말이다. 그냥 코드인 메서드 자체를 호출한 것인지 프록시를 통해 접근했는지 잘 확인해야한다.
같은 객체 내부에서 선언하면 작동 안함
| |
내부가 아닌 외부에서 호출해야 작동함
- 이 경우도 타겟 메서드 위에다가 잘 붙여야함
| |
# Transactional 속성
@Transactional 애노테이션을 선언하면 6가지 속성을 지정해 트랜잭션을 세부적으로 이용할 수 있다.
- 전파(propagation)
- 고립(isolation)
- 읽기동작(read-only)
- 타임아웃(timeout)
- rollbackFor, noRollbackFor
# Propagation
- 트랜잭션의 경계에서 이미 진행 중인 트랜잭션이 있는 지 유무에 따라 어떻게 동작할 지를 결정하는 것
- 여러 트랜잭션 적용 범위를 묶어서 커다란 하나의 트랜잭션 경계를 만들 수 있다.
- 트랜잭션 경계의 시작 지점에서 트랜잭션 전파 속성을 참조해서 해당 범위의 트랜잭션을 어떤 식으로 진행할지 결정할 수 있다.
| 진행 중인 트랜잭션 O | 진행 중인 트랜잭션 X | |
|---|---|---|
| REQUIRED | 해당 트랜잭션 사용 | 새로운 트랜잭션 생성 |
| MANDATORY | 해당 트랜잭션 사용 | 예외 발생 |
| REQUIRES_NEW | 해당 트랜잭션 보류 새로운 트랜잭션 생성 | 새로운 트랜잭션 생성 |
| SUPPORTS | 해당 트랜잭션 사용 | 트랜잭션 없이 진행 |
| NOT_SUPPORTED | 해당 트랜잭션 보류 | 트랜잭션 없이 진행 |
| NEVER | 예외 발생 | 트랜잭션 없이 진행 |
| NESTED | 중첩 트랜잭션 생성 | 새로운 트랜잭션 생성 |
REQUIRED
- 전파의 default 속성, 모든 트랜잭션 매니저가 지원
- 만약, REQUIRED 속성일 때 하나의 트랜잭션이 시작된 후 다른 트랜잭션 경계가 설정된 메서드를 호출하면 자연스럽게 같은 트랜잭션으로 묶임
MANDATORY
- 혼자서 독립적으로 트랜잭션을 진행하면 안되는 경우에 사용 가능
REQUIRES_NEW
- 항상 새로운 트랜잭션을 시작해야하는 경우에 사용
SUPPORTS
- 진행 중인 트랜잭션이 없는 경우에는, 트랜잭션이 없더라도 해당 경계 안에서 Connection 객체나 Hibernate의 Session 등은 공유할 수 있음
NESTED
- 이미 진행중인 트랜잭션이 있으면 중첩 트랜잭션을 시작, 트랜잭션 안에 다시 트랜잭션을 만드는 것
- REQUIRES_NEW는 독립적인 트랜잭션을 만드는 것이다. NESTED와는 다르다.
- 따라서, NESTED는 먼저 시작된 부모 트랜잭션의 커밋과 롤백에 영향을 받는다. 하지만 자식의 커밋과 롤백은 부모 트랜잭션에 영향을 주지 않는다.
- 예를 들어, 어떤 중요한 작업을 진행하면서 작업 로그를 DB에 저장해야 한다고 하자. 그런데 로그를 저장하는 작업은 실패를 하더라도 메인 작업의 트랜잭션까지는 롤백하지 말아야 하는 경우가 있다. 왜냐하면 힘들게 처리한 중요한 작업을 로그를 남기지 못해서 모두 실패로 만들 수 없기 때문이다. 반면에 핵심 작업에서 예외가 발생한다면 이때는 저장된 로그도 제거해야 한다.
# Isolation
- 동시에 여러 트랜잭션이 진행될 때, 트랜잭션의 작업 결과를 타 트랜잭션에게 어떻게 노출할 지 결정하는 속성
DEFAULT
- 사용하는 데이터 액세스 기술이나 DB Driver의 디폴트 설정을 따름
- 드라이버의 격리 수준 -> DB의 격리 수준 따름
- 오라클 -> READ_COMMITED
- MySQL -> REPETABLE_READ
READ_UNCOMMITTED
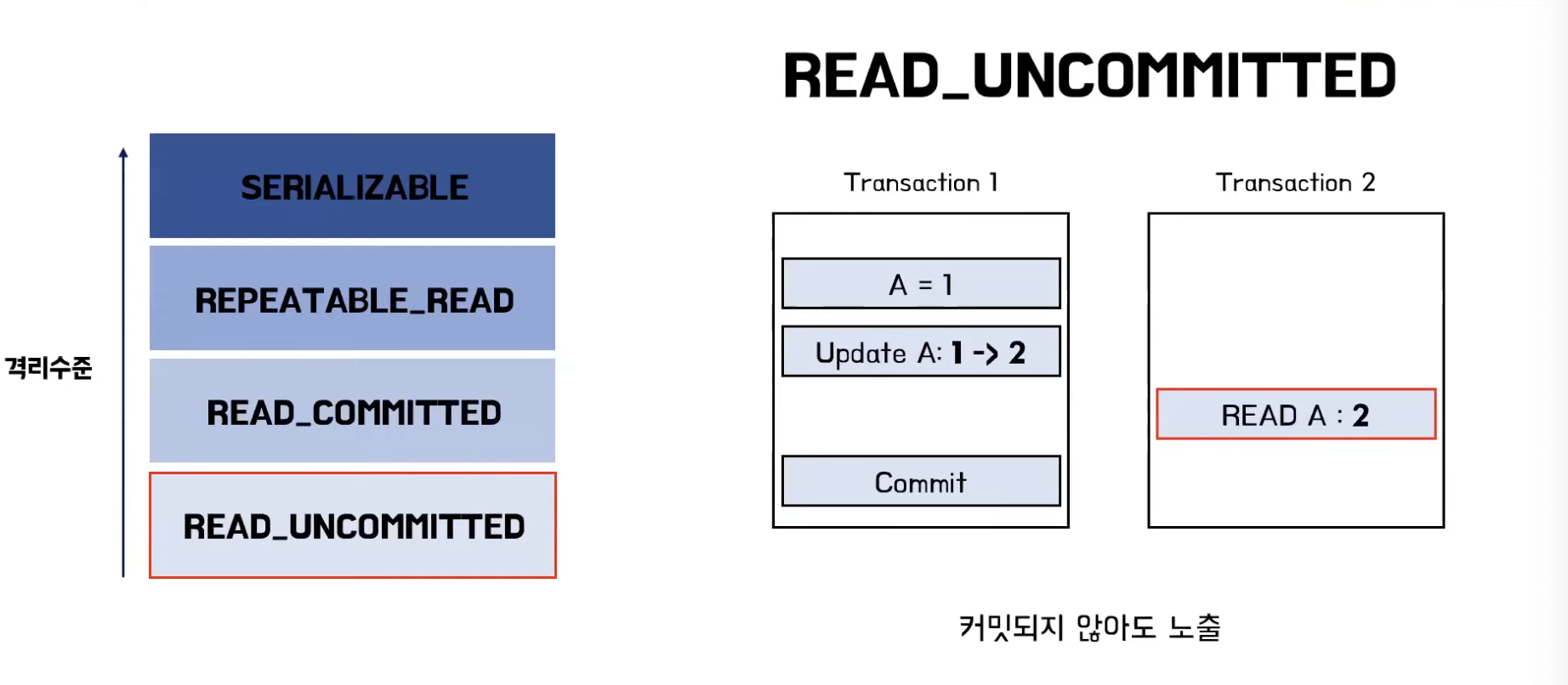
- 가장 낮은 격리 수준
- 하나의 트랜잭션이 커밋되기 이전, 변화가 다른 트랜잭션에 그대로 노출
- 더티리드 현상 발생 가능
- 트랜잭션 1이 만약 트랜잭션을 끝마치지 못하고 롤백한다면 트랜잭션 2는 무효가 된 데이터 값을 읽고 처리하기 때문에 문제가 발생
- Non_Repetable_Read 현상 발생 가능
- Phantom Read 현상 발생 가능
- 하지만 가장 빠름. 데이터의 일관성이 떨어지더라도 성능 극대화 위해 사용
READ_COMMITTED
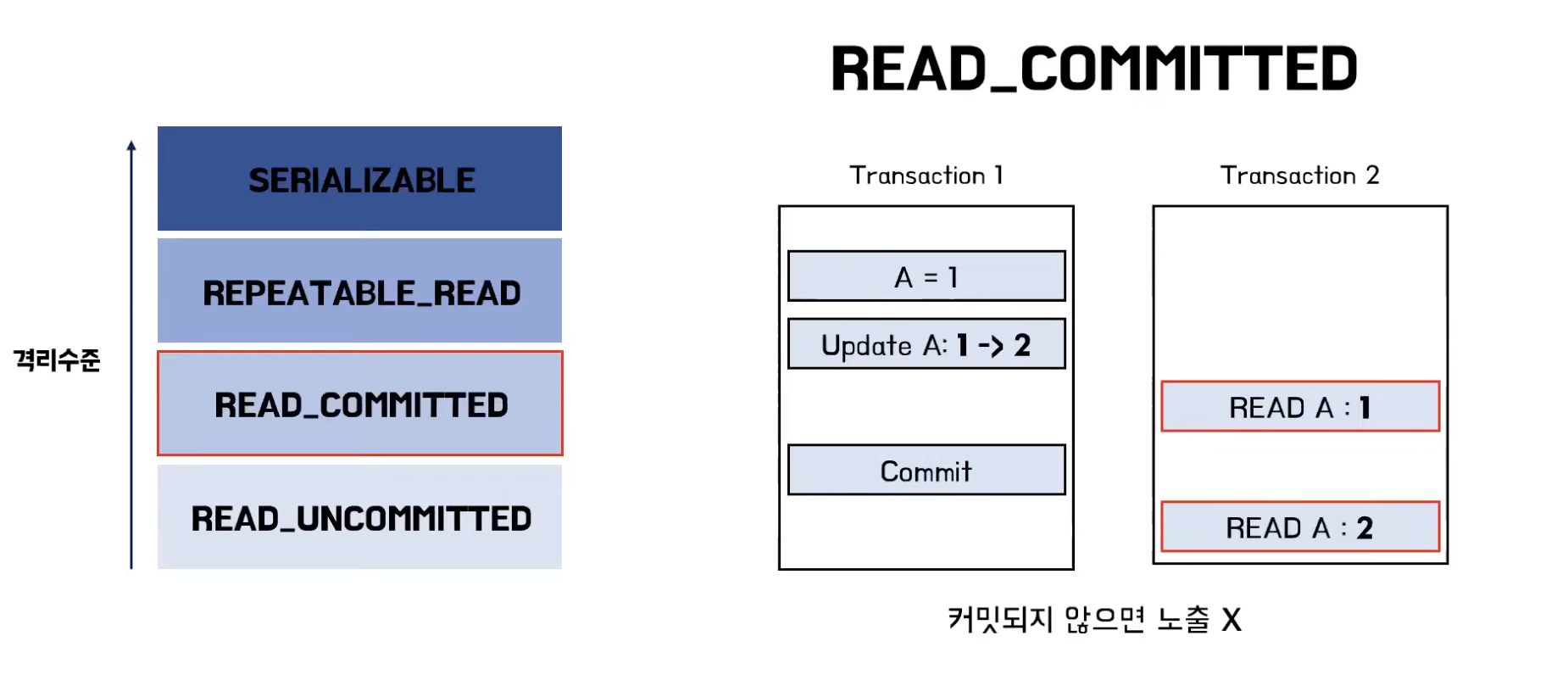
- 다른 트랜잭션이 커밋하지 않은 정보는 읽을 수 없음
- 하나의 트랜잭션이 읽은 row를 다른 트랜잭션이 수정할 수 있음
- 이 때문에 읽는 시점에 따라 같은 row를 읽어도 다른 데이터일 수 있음
- Non-Repetable Read 현상 발생 가능
- 같은 트랜잭션 내에서 select 문을 두 번 조회했을 때 두 값이 다른 값이 나오는 데이터 불일치 문제
- Phantom Read 현상 발생 가능
REPEATABLE_READ
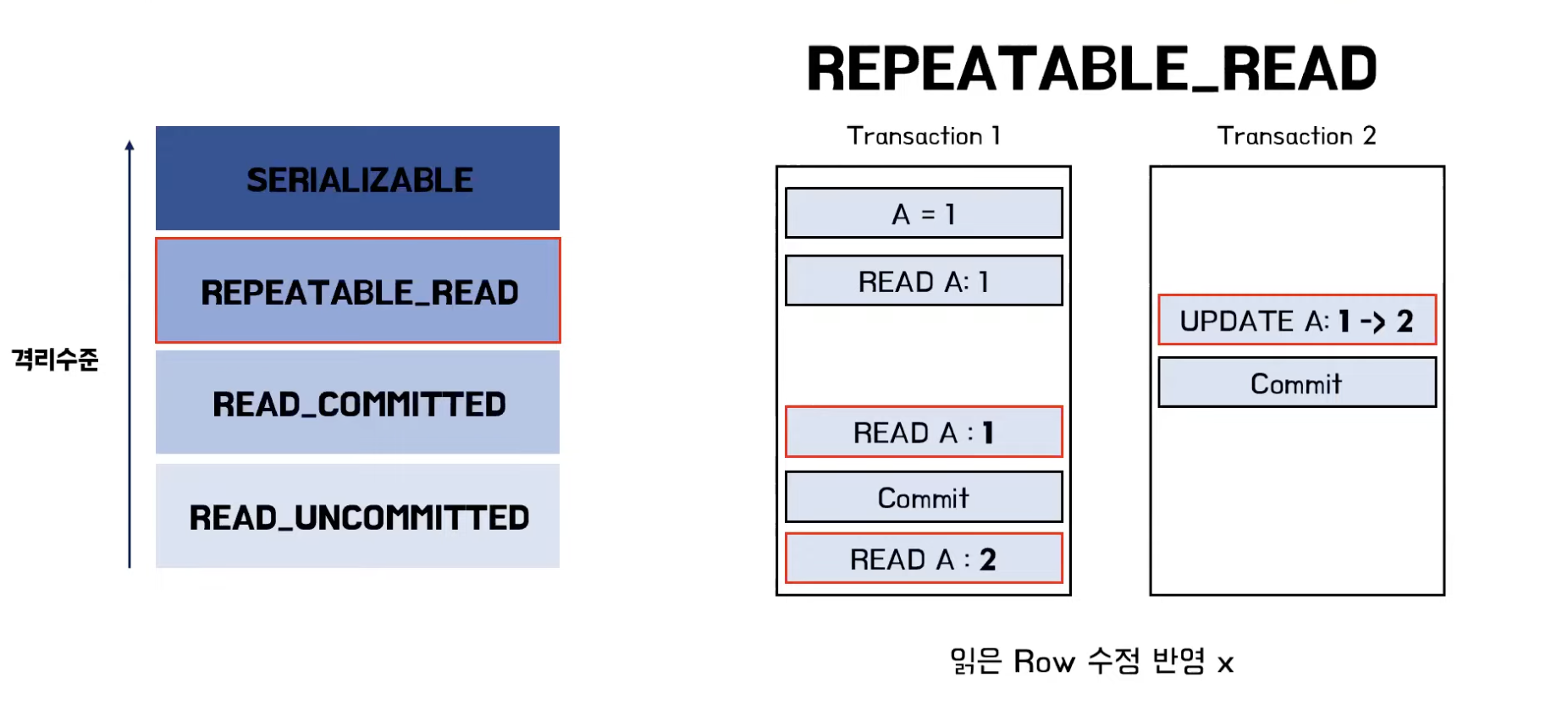
- 하나의 트랜잭션이 읽은 row를 다른 트랜잭션이 수정할 수 없게 막음
- 하지만, 새로운 row를 추가하는 것은 막지 않음
- SELECT로 조건에 맞는 row를 전부 가져오는 경우 트랜잭션이 끝나기 전에 추가된 row가 발견될 수 있음
- 트랜잭션 시작 시점에 스냅샷을 생성해서 그때 읽어온 정보들을 스냅샷으로 만든다. 스냅샷에서 정보를 가져오기 때문에 커밋되기 이전에 데이터가 반영 안됨
- Phantom Read 현상 발생 가능
- Non-Repetable Read의 한 종류
- 조건이 걸렸든 안 걸렸든 select 문을 사용할 때 나타날 수 있는 현상
- 해당 쿼리로 읽히는 데이터에 들어가는 row가 새로 생기거나 없어져 있는 현상
SERIALIZABLE
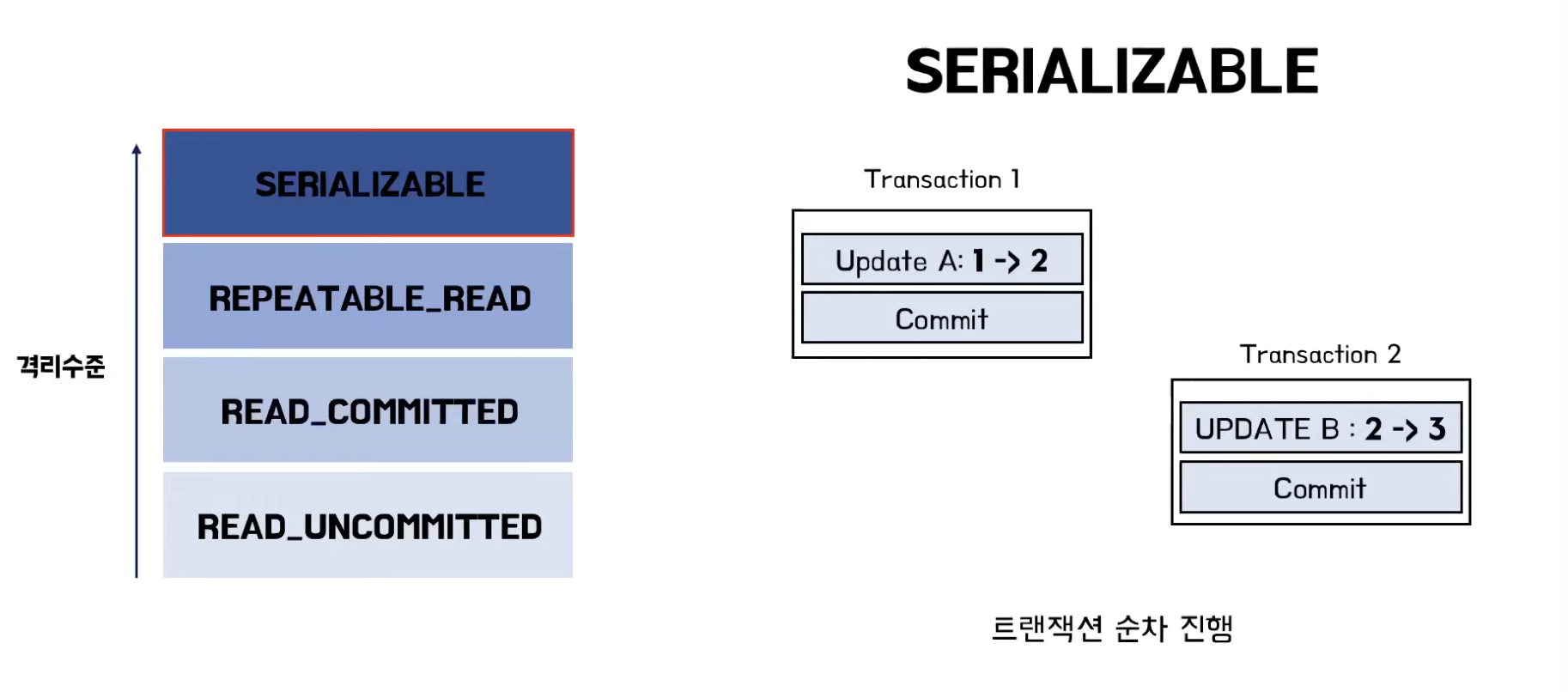
- 가장 강력한 트랜잭션 격리 수준. 이름 그대로 트랜잭션을 순차적으로 진행
- 여러 트랜잭션이 동시에 같은 테이블의 정보를 액세스 할 수 없음
- 극단적으로 안전한 작업이 필요한 경우 아니면 성능이 가장 떨어지니까 사용 X
# Timeout
- 트랜잭션에 제한시간을 지정할 수 있음. 같은 int 타입의 초 단위로 지정할 수 있고, 문자열로 지정하고 싶으면 timeoutString을 사용하면 됨
- 기본 옵션에는 제한시간이 없음. 그래서 설정할 수 있게 해주는거임
- REQUIRED, REQUIRES_NEW와 같이 새로운 트랜잭션을 시작하는 전파속성과 함께 사용 가능하도록 보완한 것
# readOnly
2가지 목적으로 읽기 전용 설정이 가능
- 트랜잭션 내에서 데이터를 조작하려는 시도를 막음 (쓰기 작업)
- 읽기 전용으로 설정하여 성능을 최적화
ReadOnly 성능 이점
- JPA를 사용할 경우,
readOnly = true설정을 주면 영속성 컨텍스트에 플러시가 일어나지 않으므로 쓰기, 수정, 삭제 작업이 동작하지 않는다. 또한, 스냅샷 저장, 비교 등의 무거운 작업을 하지 않아서 성능이 향상된다. - 데이터베이스가 master와 slave로 나누어져 있다면,
readOnly = true설정을 주었을 때 읽기 전용인 slave를 호출하게 된다. 즉, 상황에 따라 데이터베이스 서버 부하를 줄일 수 있다.
# 롤백/커밋
Spring은 디폴트로 UnCheckedException 과 Error에 대해서 롤백 정책을 설정한다. @Transactional에서 런타임 예외가 발생하면 롤백하고, 예외가 발생하지 않았거나 체크 예외가 발생하였다면 커밋한다는 의미이다.
- CheckedException을 커밋 대상으로 삼은 이유?
- 체크 예외가 예외적인 상황에서 사용되기 보다는 반환값을 대신하여 비즈니스 적인 의미를 담은 결과로 많이 사용되기 때문
- UnCheckedException을 롤백 대상으로 삼은 이유?
- 데이터 액세스 기술의 예외는 런타임 예외로 전환하여 던지므로
rollback-for
- 기본적으로 RuntimeException 발생 시 롤백
- CheckedException 이지만 롤백 대상으로 삼고 싶으면 사용
no-rollback-for
- 롤백 대상인 RuntimeException을 커밋 대상으로 지정
# 참고
- 프로그래머스 데브코스 OSIV - 이건우
- 제이온 님의 Connection Pool 내용 블로그
- 제이온 님의 스프링이 제공하는 트랜잭션의 핵심 기술 내용 블로그
- 테코톡 - 후니의 스프링 트랜잭션
- Tase-k Devlog spring annotation 트랜잭션
- 테코톡 - 예지니어스의 트랜잭션