1주차 - 불변객체, Exception
1주차 스터디
TOPIC - 01
불변 객체가 무엇인지 설명하고 대표적인 Java의 예시를 설명해주세요.
TOPIC - 02
Checked Exception과 Unchecked Exception은 어떤 차이가 있는지 설명해주세요.
# TOPIC 01 - 불변객체
# 복사 시리즈
얕은 복사
- 값을 복사하는 것이 아닌, 주소값을 복사
- 따라서, 원본이 바뀌면 원본을 얕은 복사한 객체들도 같이 변경됨 (참조하고 있으니까)
깊은 복사
- 내부 요소들 전부 복사하여 새로운 객체 생성
- 객체가 가리키는 주소값이 원본과 모두 다름
- 원본이든 내부 요소이든 바뀌어도 영향 없음
방어적 복사
- 생성자에서 사용 시 입력받은 인자를 내부 필드로 초기화
- 하지만, 인자의 내부 요소들은 그대로 원본 내부요소를 가리킴
getter메서드에서 내부의 객체를 반환할 때, 객체의 복사본을 만들어 반환하는 것- 객체의 내부 필드 값을 외부로부터 보호하는 것이 목적
- 생성자에서 사용 시 입력받은 인자를 내부 필드로 초기화
Unmodifiable Collection
- 원본 컬렉션으로의 수정 메서드를 할 수 없는 Read Only
unmodifiableList()메서드를 통해 리턴되는 리스트는 읽기 용도로만 사용 가능- 하지만,
unmodifiable과immutable은 다르다.unmodifiable이 불변성을 보장해주지는 않음- 원본 자체에 대한 수정이 일어나면
unmodifiableList()메서드를 통해 반환되었던 리스트 또한 변경이 일어남
즉, 원본과의 주소 공유를 끊으려면 깊은 복사 or 방어적 복사를 해야함
1. 생성자의 인자로 객체를 받았을 때
- 외부에서 넘겨줬던 객체를 변경해도 내부 객체는 변하지 않아야 하므로 방어적 복사가 적절
2. getter 를 통해 객체를 리턴할 때
- 이러한 상황에선 방어적 복사와 Unmodifiable Collection 중 하나를 사용하여 값을 리턴하는것이 적절하다.
# 불변객체란?
불변객체(immutable object)는 말 그대로 변하지않는 객체로 객체가 생성된 후 내부 상태가 변하지 않는 객체를 의미한다. 객체가 변하지 않는다는 것은 신뢰도가 높아진다는 의미이다.
반대 개념은 가변객체(mutable object)로 객체 생성 이후에도 상태를 변경할 수 있음
객체 생성 이후 내부 상태가 변하지 않으니, 불변객체는 Setter 메서드를 제공하지 않는다.
혹은 방어적 복사(defensive-copy)를 통해 제공한다.
final을 붙이면 불변객체가 되는 것인가?
final 예약어 사용시
- 변수 : 값을 수정할 수 없는 상수로 만듦
- 메서드 : 오버라이딩을 할 수 없게 만듦
- 클래스 : 상속이 불가능하게 만듦
즉, 객체 선언 시 final을 사용해도 객체 내부 상태는 변경할 수 있다
# 불변객체 장점
쓰레드에 안전하여 멀티-쓰레드 환경에서 동기화를 고려하지 않아도 된다. (thread-safety)
불변객체를 필드로 사용할 때 방어적 복사가 필요없다.
불변객체는 내부상태가 변경되지 않으므로, Map Key와 Set 요소로 사용하기에 적합하다.
불변객체를 한 번 메모리에 할당하면 같은 객체를 계속 호출하여도 새롭게 할당하지 않아도 되므로 Garbage Collector의 성능을 높힐 수 있다.
# 불변객체 단점
모든 객체의 불변성을 보장하게 된다면, 상태 변화가 필요한 경우 새로운 객체를 생성해야 한다는 단점이 있고, 새로운 객체를 많이 생성하는 경우 성능 문제가 발생할 수 있다.
하지만 Oracle에 의하면, 객체 생성 비용에 대한 영향은 종종 과대평가되며, 불변 객체를 활용할 때의 이점들이 이런 단점을 상쇄시킨다고 한다.
# 불변객체 생성방법
setter메서드 제공 X- 내부 상태값을 변경하지 않기 위하여
setter메서드를 제공하지 않는다.
- 내부 상태값을 변경하지 않기 위하여
클래스를
final로 선언- 클래스를
final로 선언하면 해당 클래스를 다른 클래스에서 상속받는게 불가능, 따라서 부모 클래스에 선언되어 있는 메서드 Overriding 불가능 final을 선언했다고 객체가 immutable 한 것을 보장할 수 있지는 않음. 위에서 설명한 이유처럼 객체 내부상태는 여전히 바뀔 수 있음- 즉, 1번 방법이랑 같이 써야하는 것
- 클래스를
모든 필드를 final과 private을 사용해서 선언
- 변수에 final을 붙이면 재할당이 불가능하게 상수 취급됨
- 인스턴스 변수
- Primitive type, 원시타입 : final로 선언하여 불변성 유지 가능
- Reference type, 참조타입 : final로 선언하면 참조 대상이 바뀔 수 없다는 의미일 뿐 불변성을 보장할 수는 없다. 객체 내부 상태가 바뀔 수 있기 때문이다.
- 따라서, 접근 제어자를 private으로 선언하여 해당 클래스만 해당 필드에 대한 접근 권한을 가지게 변경, setter 메서드를 제공하지 않으니 외부 클래스로부터 접근 차단하니까
객체를 생성하기 위한 생성자 or 정적 팩토리 메서드 추가
- 생성자를 통해 초기화되는 필드들은 깊은 복사를 통한 참조 대상 재할당
- 생성자를 통해 초기화되는 인스턴스 변수들이 Reference Type이면 깊은 복사를 통해 참조하는 객체 내부의 값이 변경되는 것을 방지할 수 있음
- getter 메서드를 객체의 깊은 복사본을 반환하도록 함
- getter 메서드가 실제 객체에 대한 reference를 반환하는 대신 깊은 복사를 통해 생성한 객체에 대한 reference를 반환하여, 반환받은 객체를 사용할 때 실수로라도 기존 객체를 건드릴 수 없게
- 생성자를 통해 초기화되는 필드들은 깊은 복사를 통한 참조 대상 재할당
인스턴스 필드에 가변객체가 포함된다면 방어적 복사를 이용하여 전달
코드 예시보기
| |
- 불변객체 생성 방법에 따라 생성 이후 객체의 상태를 바꾸는 메서드를 실힝해도 내부 상태가 변경되지 않은 결과를 확인하였음.
# String
String은 대표적인 불변객체의 예시이다.
- 변수에 할당되면 참조를 업데이트하거나 내부 상태를 어떤 방법으로도 변경할 수 없기 때문
String 객체를 생성하는 방법 2가지
- String literal
""사용 - new 연산자 사용
- String literal
| |
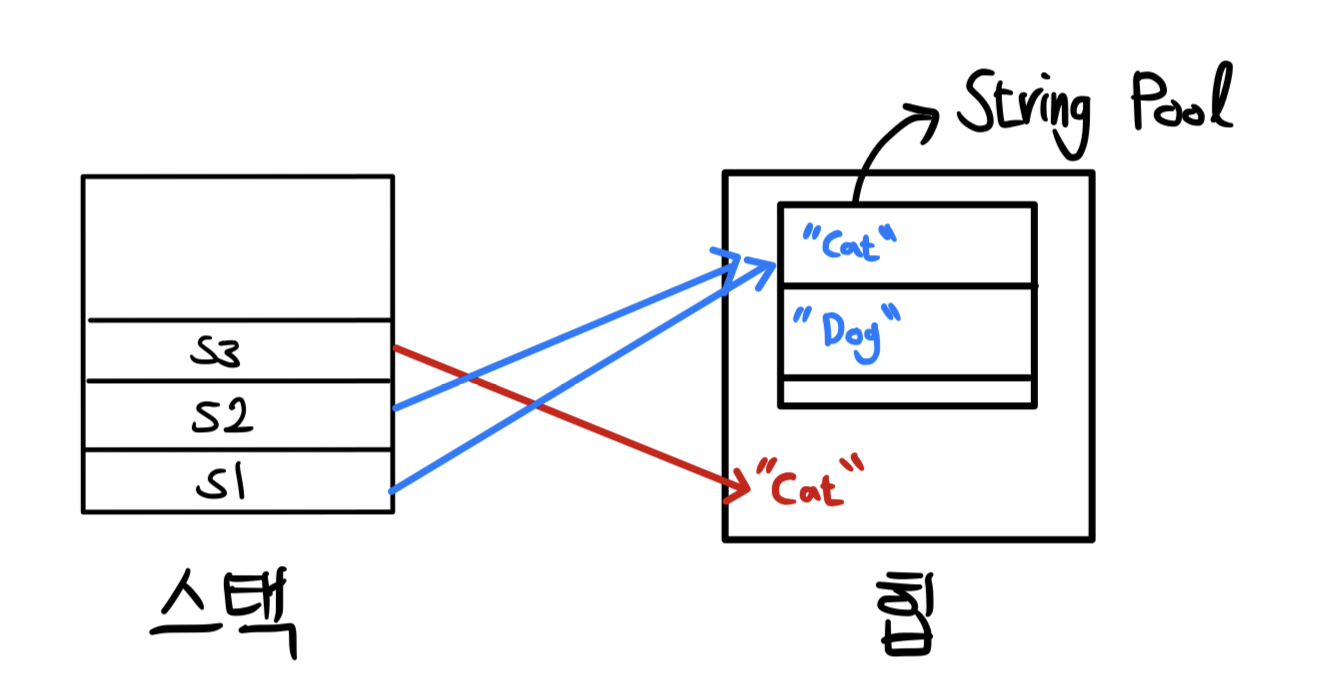
literal로 생성한 객체는 String pool에 들어간다.
- 생성한 객체의 값이 이미 존재한다면, String pool의 reference를 참조한다.
- 문자열 리터럴을 캐싱하고 재사용하기 때문에 Heap 공간을 많이 절약할 수 있음
new 연산자로 생성하면 상수 풀에 있어도 Heap 영역에 새로운 객체를 생성한다.
- 이는 불변객체인 String의 장점을 누리지 못한다는 의미
intern()메서드- String pool에 String 객체 존재 -> 그 객체를 그대로 return
- String pool에 String 객체 존재 X (new 연산자로 생성한 경우)
- 호출된 String 객체를 String pool에 추가하고 객체의 reference를 return
String pool, Constant String pool 은 같은 의미 Constant Pool, Runtime Constant Pool 등을 이해하려면 블로그 게시글 참고
# String이 불변인 이유
- 성능 (Performance)
- 상수 풀을 이용하여 캐싱하고 재사용하기 때문에 Heap 공간을 절약하여 성능 높힘
- 동기화 (Synchronization)
- 불변 객체는 값이 바뀔 일이 없어서 멀티스레드 환경에서
Thread-safe - 동시에 실행되는 여러 스레드에서 공유할 수 있다. 스레드가 값을 변경하면 동일한 문자열을 수정하는 대신, String pool에 새로운 문자열이 생성되기 때문에 스레드가 안전함
- 불변 객체는 값이 바뀔 일이 없어서 멀티스레드 환경에서
| |
- 해시코드 캐싱 (Hashcode Caching)
- String은 데이터 구조로도 많이 사용 (HashMap, HashTable, HashSet)
- String의
hashCode()메서드 구현을 보면 아직 hash 값을 계산한 적이 없을 때 최초 1번만 실제 계산 로직을 수행하고, 이후부터는 해당 값을 그냥 반환만 하도록 overriding 되어 있다. (계산해놓았던 해시코드를 재사용하는 것) - String이 불변이기 때문에 이렇게 caching이 가능하다는 이점을 활용할 수 있는 것 (값이 변하지 않기 때문에 위와 같이 캐싱해서 사용할 수 있는 것)
HashMap, HashSet 등 키를 불변형으로 많이 쓰는데, 이걸 가변형이라고 가정하면 어떤 문제가 있을까?
만약에 문자열이 가변이라고 하면 매번 해쉬값이 변하니까 이 데이터가 과연 맞는 값일까? 의문점을 가질 것이다. 키가 바뀌다보면 이게 A로, B로 확확 바뀌면 내가 찾고자 하는 값을 찾기 위하여 원하지 않게 두 번,세 번,네 번 계산을 해야하니까 무조건 key 값은 불변자료로 넣어서 캐싱을 하기 쉽게, 혹은 재사용하기 쉽게 HashSet이나 HashMap에서의 key는 불변성을 유지하고 있다.
간단하게 말해서 캐싱처리를 해서 재사용하기 쉽게, 메모리 공간처럼 자원을 아껴서 조금 더 빠르게 구동할 수 있게 하기 위함이다. Hash 함수를 쓰면 보통 O(1) 만큼의 값을 쳐줄 수 있는 성능상으로도 되게 유리해지고 멀티스레드나 동기성을 쉽게 다룰 수도 있는데 가변상태로 하게 되면, 디버깅을 할 수는 있겠지만 딥하게 파고드는 디버깅을 할 수도 없는 특징이 있다.
- 보안 (Security)
- 문자열은 Java 애플리케이션에서 사용자 이름, 암호, 연결 URL, 네트워크 연결 등과 같은 중요한 정보를 저장하는 데 널리 사용됨. 클래스를 로드하는 동안 JVM 클래스 로더에서도 광범위하게 사용.
- String이 불변 객체가 아니라면 메서드를 호출했던 클라이언트는 String에 대한 참조가 메서드를 호출 이후에도 남아있다. 따라서 보안 검사를 실시한 이후에도 이 문자열이 안전하다고 보장할 수 없다. 메서드를 호출했던 클라이언트가 String에 대한 참조를 계속 가지고 있기 때문에 문자열을 변경할 수 있다는 가능성이 남아있다.
- 이러한 보안 이슈 때문에 String을 불변객체로 만들었음
# StringBuilder, StringBuffer
- String을 단순 문자열로 활용하고 싶을 때는 불변객체가 적절하지 않을 수 있음
문자열 연산 +이 많은 경우
- 문자열 연산 등으로 기존 객체의 공간이 부족해지는 경우, 기존의 버퍼 크기를 늘려 유연하게 동작하는 가변객체
- StringBuffer는 각 메서드별로 Synchronized Keyword가 존재하여, 멀티스레드 환경에서도 동기화를 지원.
- StringBuilder는 동기화를 보장하지 않음.
정리
String : 문자열 연산 자체가 적고 멀티스레드의 경우
StringBuffer : 문자열 연산이 많고 멀티스레드의 경우
StringBuilder : 문자열 연산이 많고 단일스레드고 동기화를 고려하지 않아도 되는 경우
보통 Java-Spring에서는 멀티스레드 환경을 지원하고 있기 때문에 보통은 String, StringBuffer를 사용하는 편이다.
# (심화) 객체 생성비용 최소화
생성비용이 많이 드는 객체가 반복해서 필요하다면 어떻게 해야할까?
- 정답 후보 3가지가 있고, 결론적인 방법은 필드캐싱이다.
static final을 클래스 내부 필드에 해놓는 필드 캐싱 방법- 불변객체 시작하는 것을 클래스를 사용할 때만 맞춰서 하는 lazy initialization(지연 초기화) 방법
- 인스턴스가 생성이 되는지 존재하지 않는지에 대해서 2번씩 체크하는 Double-checked Locking Pattern
상황마다 다르겠지만, 보통 지연 초기화는 코드를 더 복잡하게 만들어서 성능 개선이 크게 되지 않아서 잘 사용하지 않는다고 한다. 실무에서는 필드 캐싱을 많이 사용한다.
보통 사람들은 Double-checked Locking을 생각할 수 있는데, 그러면 체크를 하면서 확인을 해야하고 이거에 따라 절차를 밟아가는 것이라서 보통은 캐싱처리를 하고 바로바로 사용하려고 한다. 실무에서는 메모리를 쪼~끔 더 쓰고 그냥 빠르게 쓰자는 의미로 캐싱해서 쓴다. 아니면, 메모리를 대체해줄 수 있는 Redis, NoSQL 같은 것으로 좀 빠르게 쓰자!라고 생각한다.
# (심화) DCLP 지양에 관한 이야기
사실 DCLP는 Java와는 맞지 않는 패턴이다.
- DCLP는 멀티스레드 환경에서 안전하지 않다.
- 그 이유는 jvm이 out of order writes를 지원하기 때문인데,
- 멀티스레드 환경에서 그에따라 입력되는 순서가 보장되지 못한다.
- 순서 입력을 보장받기위해 volatile 키워드를 가용할 수 있습니다.
- volatile 키워드의 기능은따라 cpu caching이 아니라 메인메모리에 직접 작성하는데,
- jvm의 최적화를 끈다는 단점이 있고,
- 입력한 순서를 복사하여 jvm에 재입력 한다는 단점이 있다.
- 더불어 volatile 키워드가 멀티스레드 자체에서 race condition과 상기했듯이 memory visibility에 취약점을 가지고 있으므로, 결론적으로 보면 지양해야한다.
싱글톤 패턴은 생성자가 여러 차례 호출 되어도 실제로 생성되는 인스턴스는 단 1개이고, 최초 생성 이후 호출된 생성자는 최초에 생성한 객체를 리턴하는 형태이다. 그러나, 멀티스레드 환경이라면 어떻게 될까? 인스턴스를 차지하기 위하여 스레드 간 경쟁이 일어나게 된다. 이 문제를 해결하기 위하여, 여러 가지 해결방법을 생각했는데 그중 DCLP는 자바와는 사실 잘 맞지 않는 방법이다.
| |
흐름을 살펴보면
- 스레드1이 null이니까 (1)을 통과하고 뮤텍스의 제어권을 획득함.
- 스레드2도 null이지만 스레드1이 뮤텍스의 제어권을 가지고 있으니 여기에서 블락됨
- 스레드1은 (2) -> (3)을 거쳐 싱글톤 자원을 만들고 인스턴스에 할당. 끝나면서 리턴
- 스레드2가 뮤텍스의 제어권 획득하고 null인지 확인하고 (2) -> (3) 진행
이렇게 흐름상 이론은 완벽해보이지만, DCLP는 자바 플랫폼 메모리 모델과는 맞지 않는 방법이다.
- 조건이 두 개라서 mutex로 (2) 이전까지는 흐름을 제어할 수 있다.
- mutex 자체가 key를 기반으로 한 상호배제 기법이니까 객체를 소유한 스레드만이 (2)에 접근할 수 있다.
- 그러나, 자바의 메모리 모델은 “out-of-order-write”를 지원하기 때문에 메모리에 작성되는 순서를 보장하지 않는다. 하나의 스레드가 다른 스레드에 의해 인터럽트 된다면 생성자를 완료하기 이전에 이미 double-checking locking이 실패하는 것이다.
정리하자면, 스레드1이 작업을 끝내고 뮤텍스 제어권을 획득한 스레드2가 (2)에 진입했을 때 초기화 작업을 끝냈을 것이라는 보장이 없다는 의미이다.
그렇다면 volatile 키워드를 붙여서 “메인 메모리에 저장할 것”이라고 명시한다면 괜찮지 않을까? 멀티스레드 환경에서 volatile 변수의 초기값을 필요로 하고 새로운 값이 이 초기값을 근거로 한다면, volatile을 붙여도 더이상 정확한 가시성을 보장하지 못한다. 변수를 읽고 새 값을 쓰는 이 사이의 짧은 차이가 경합을 일으킨다. 또, 많은 JVM이 volataile의 순차적 영속성 기능을 구현하지 않기 때문에 결과적으로 volatile을 써도 보장할 수 없다는 의미이다.
따라서, DCLP는 지양되어야 한다.
# TOPIC 02 - Exception
# Error, Exception
- 컴파일 에러 : 컴파일 시에 발생하는 에러
- 런타임 에러 : 실행 시에 발생하는 에러
- 논리적 에러 : 실행은 되지만, 의도와 다르게 동작하는 것
Java에서는 실행 시(runtime) 발생할 수 있는 프로그램 오류를 에러(Error)와 예외(Exception)로 구분하였다.
- Error : 메모리 부족(OutOfMemory), 스택오버플로우(StackOverFlowError)와 같이 일단 발생하면 복구할 수 없는 심각한 오류라서 개발자가 예측해서 프로그램 코드에 어떠한 대비는 불가능
- Exception : Exception handling과 같이 예외 처리하는 방법을 통해 개발자가 예측하여 프로그램 코드에 대비 가능
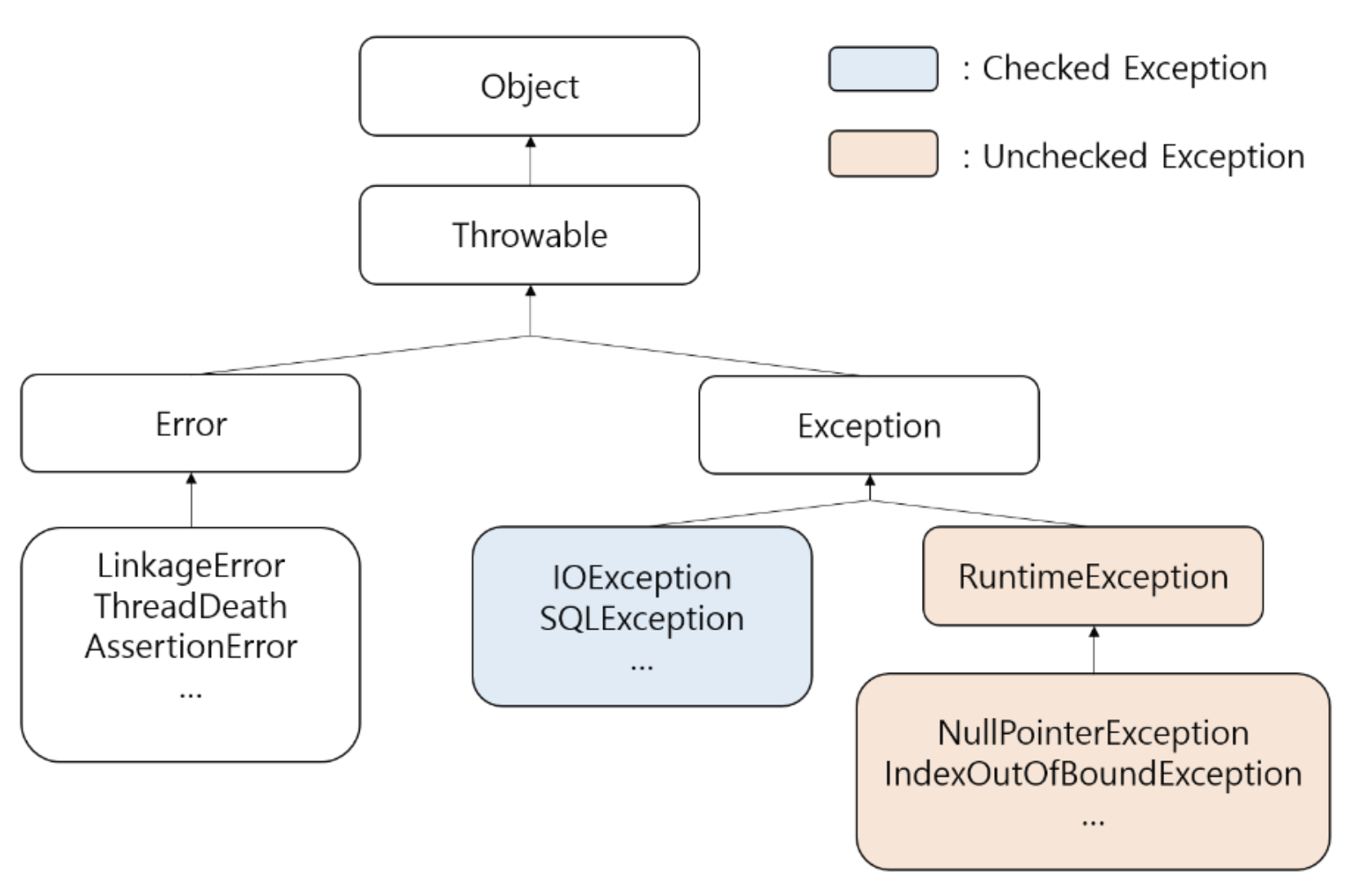
# Checked vs Unchecked
- Checked Exception : Runtime Exception을 상속하지 않는 Exception
- ex) FileNotFoundException, ClassNotFoundException, IOException, SQLException
- Unchecked Exception : Runtime Exception을 상속하는 Exception
- ex) NullpointerException, IndexOutOfBoundException, ArithmeticException
| Checked Exception | Unchecked Exception | |
|---|---|---|
| 확인 시점 | 컴파일 시점 | 런타임 시점 |
| 처리 여부 | 반드시 예외처리 O | 예외처리 안해줘도 됨 |
| 스프링에서 DB 트랜잭션 처리 기본 설정값 | 예외 발생 시 Rollback X | 예외 발생 시 Rollback O |
Exception Handling에 관해서는 2주차 스터디 참고
Spring에서의 DB 트랜잭션 처리
@Transactional 애노테이션에서는 의도해서 모든 경우의 수를 처리하지 않는 이상 롤백이 되지 않는다. 결국, Runtime Error를 발생시키지 않는다는 뜻이다. 정리하자면, 모든 경우의 수를 따져 try catch 해서 throw 하지 않으면 롤백이 되지 않아서, Runtime Error가 발생하지 않아 예외처리가 힘들다는 특징이 있다. (스터디 내용)
Spring은 디폴트로 UnCheckedException 과 Error에 대해서 롤백 정책을 설정한다. 물론, 기본 설정값이 그렇다는 것이지 옵션을 설정하여 원하는대로 변경할 수 있다.
참고링크1, 참고링크2 이 파트는 @Transactional 공부하고 다시 돌아오기
(추가)
Checked Exception이 뜬다는거 자체가 컴파일 시점에 오류가 발생되는건데 @Transactional 애노테이션 붙인 트랜잭션 안에서 예외가 처리돼도 롤백되지 않는다. 왜냐하면, 스프링 기본 설정이 Unchecked와 Error에 관해서 롤백 정책을 결정하기 때문이다.
결과적으로 체크드든 언체크든 throw 무조건 해주자 !
# 참고
- 얕은 복사 / 깊은 복사 / 방어적 복사
- 방어적 복사 vs Unmodifiable Collection
- Unmodifiable Collection 예시
- https://dev-cool.tistory.com/23
- volatile 키워드
- 멀티스레드 환경에서의 싱글톤
- C#의 DCLP
- (원본) Java와 DCLP는 맞지 않다
- (번역본) Java와 DCLP는 맞지 않다