10. 클러스터간 데이터 미러링하기
여러 데이터센터에 카프카 클러스터를 구축해야하는 경우가 있다. 카프카 커넥트를 활용한 미러메이커가 어떤 식으로 클러스터 간 데이터를 미러링하는지 알아보자.
2개 이상의 클러스터가 서로 완전히 분리되어 있는 경우
- 서로 다른 부서에 속해 있거나 다른 용도로 사용되어, 한쪽에 있는 데이터를 다른 쪽으로 복사할 이유 없는 경우
- 서로 다른 서비스 수준 협약 (SLA, Service-Level Agreement) 혹은 워크로드 때문에 하나의 클러스터에서 여러 용도를 커버할 수 없는 경우
- 서로 다른 보안 요구조건
복제 (replication) : 카프카 클러스터에 속한 카프카 노드 간의 데이터 교환
미러링 (mirroring) : 카프카 클러스터 간의 데이터 복제
# 클러스터간 미러링 활용 사례
지역 및 중앙 클러스터
지리적으로 분산 된 지역, 도시 , 대륙 간 하나 이상의 IDC를 가진 경우, 각각에 카프카 클러스터가 설치된 경우
- 보통의 애플리케이션
- 로컬 클러스터만 사용하는 것으로 충분
- 여러 IDC의 데이터를 필요로 하는 애플리케이션
- 다른 IDC의 카프카 클러스터의 데이터 필요 → 미러링 솔루션 필요
예를 들어, 수요와 공급에 따라서 가격을 조정해야하는 회사
- 사무실을 운영 중인 각각의 도시에 IDC를 가짐
- 모든 IDC에서 각 지역의 수요/공급에 대항 정보를 수집
- 이 모든 데이터는 중앙 클러스터로 미러링 됨
- 비즈니스 분석가들이 분석
고가용성과 재해 복구
다른 곳에서의 데이터가 필요하지 않다고 하더라도 고가용성(High Availability), 재해 복구(Disaster Recovery)를 위해서라면 다중 IDC에 카프카 클러스터를 구축해야할 필요가 있다.
규제
- 나라마다 있는 카프카 클러스터별로 서로 다른 설정, 정책 시행해야 할 수 있음
- e.g. 데이터 보존 기간
클라우드 마이그레이션
- e.g. 새로운 애플리케이션이 클라우드에 배포
- 이 애플리케이션이 온프레미스 IDC에서 실행되는 애플리케이션에 의해 업데이트 됨
- 온프레미스 DB에 저장되는 데이터를 필요로 하는 경우
- 카프카 커넥트 사용하여 DB의 변경 내역을 로컬 카프카 클러스터로 내보냄
- 클라우드 환경에서 실행되는 카프카 클러스터로 미러링
- 새로운 애플리케이션이 해당 데이터 사용 가능 !!
엣지 클러스터로부터의 데이터 집적
- 연결성(connectivity)이 제한된 소형 기기(e.g. IoT 기기)를 사용하여 데이터 생성 (엣지 클러스터)
- 가용성 높은 집적용 클러스터(aggregate cluster)가 엣지 클러스터로부터 데이터 수집
가용성이 높은 집적용 클러스터는 엣지 클러스터가 오프라인 상태가 되더라도 연속적인 작업 수행 가능
# 다중 클러스터 아키텍처
아키텍처 원칙 (해당 장에서 설명할 아키텍처 대부분에 해당하는 원칙)
- 하나의 데이터센터당 한 개 이상의 클러스터를 설치
- 각각의 데이터센터 간에 각각의 이벤트를 에러로 인한 재시도를 제외하면 정확히 한 번씩 복제
- 원격 데이터센터에 쓰는 것보다 원격 데이터센터에서 읽어오는 것이 더 나음
설명에 앞서, 토스 테크 블로그에 게시된 내용을 잠깐 소개한다.
다중 데이터센터 이중화 아키텍처에서 아래와 같은 방식 채용 가능
- Active - Active 구성
- 서로 독립적인 카프카 클러스터를 양쪽 데이터센터에 구성하는 방식
- MM2 (MirrorMaker2) 같은 툴을 이용해 양방향 데이터 미러링 필요
- Stretched Cluster 구성
- 양쪽 데이터센터에 분리된 노드를 하나의 Kafka 클러스터로 묶어서 구성
- 물리적으로 분리돼있지만, 한 개의 Kafka 클러스터라 별도 데이터 미러링 작업이 필요 없이 동기화 됨
- 자세한 내용은 토스 테크 블로그 참고
# IDC 간 통신의 문제들
높은 지연 (high latency)
- 두 카프카 클러스터 간 거리 ⇧ + 네트워크 홉(hop) 개수 ⇧ → 통신 지연 ⇧
제한된 대역폭 (limited bandwidth)
- 대역폭 : 특정 시간동안 전송할 수 있는 데이터의 양, 대역폭이 높을 수록 더 빠르게 데이터 전송 가능
- 광역 통신망 (WAN, wide are network)
- 일반적으로 단일 IDC 내부보다 훨씬 낮은 대역폭 가짐 (데이터 전송 속도 느림)
- 사용 가능한 대역폭 시시각각으로 변함
- 지연이 높아짐 → 사용 가능한 대역폭 활용하는 것 어려워짐
더 높은 비용 (high cost)
- 클러스터 간 통신 → 더 많은 비용
- 공급자가 서로 다른 IDC, 리전, 클라우드와 데이터 전송에 과금함
기본적으로 아파치 카프카의 브로커, 클라이언트는 하나의 IDC 안에서 실행되도록 설계, 개발, 테스트, 조정됨
- 개발자들은 브로커-클라이언트 사이에 낮은 지연, 높은 대역폭 가진 상황을 상정하고 개발함
- 각종 타임아웃 기본값, 다양한 버퍼의 크기 등 위 상황에 맞춰 설정됨
- → 카프카 브로커를 서로 다른 데이터 센터에 나눠서 설치하는 것을 권장 ❌
원격 IDC에 데이터를 쓰는 것은 피하는 것이 좋음
- 만약 써야한다면, 더 높은 통신 지연, 네트워크 에러 발생 가능성 감수해야함
- 프로듀서 전송 재시도 횟수 ⇧ → 네트워크 에러 처리 가능
- 전송 시도 중 레코드를 저장해두는 버퍼의 크기 증가 ⇧ → 높은 통신 지연에 대응
원격 클러스터 간 복제가 필요한 경우
- 원격 브로커 간의 통신과 원격 프로듀서-브로커 통신 배제 → 원격 브로커-컨슈머 통신이 남음
- 네트워크 단절이 일어났을 때 컨슈머가 데이터를 읽을 수는 없게 됨
- 레코드 자체는 연결이 복구되어 컨슈머가 읽을 수 있게 될 때까지 카프카 브로커 안에 안전하게 저장
- → 네트워크 단절로 인한 데이터 유실의 위험성은 존재 ❌
# 허브-앤-스포크
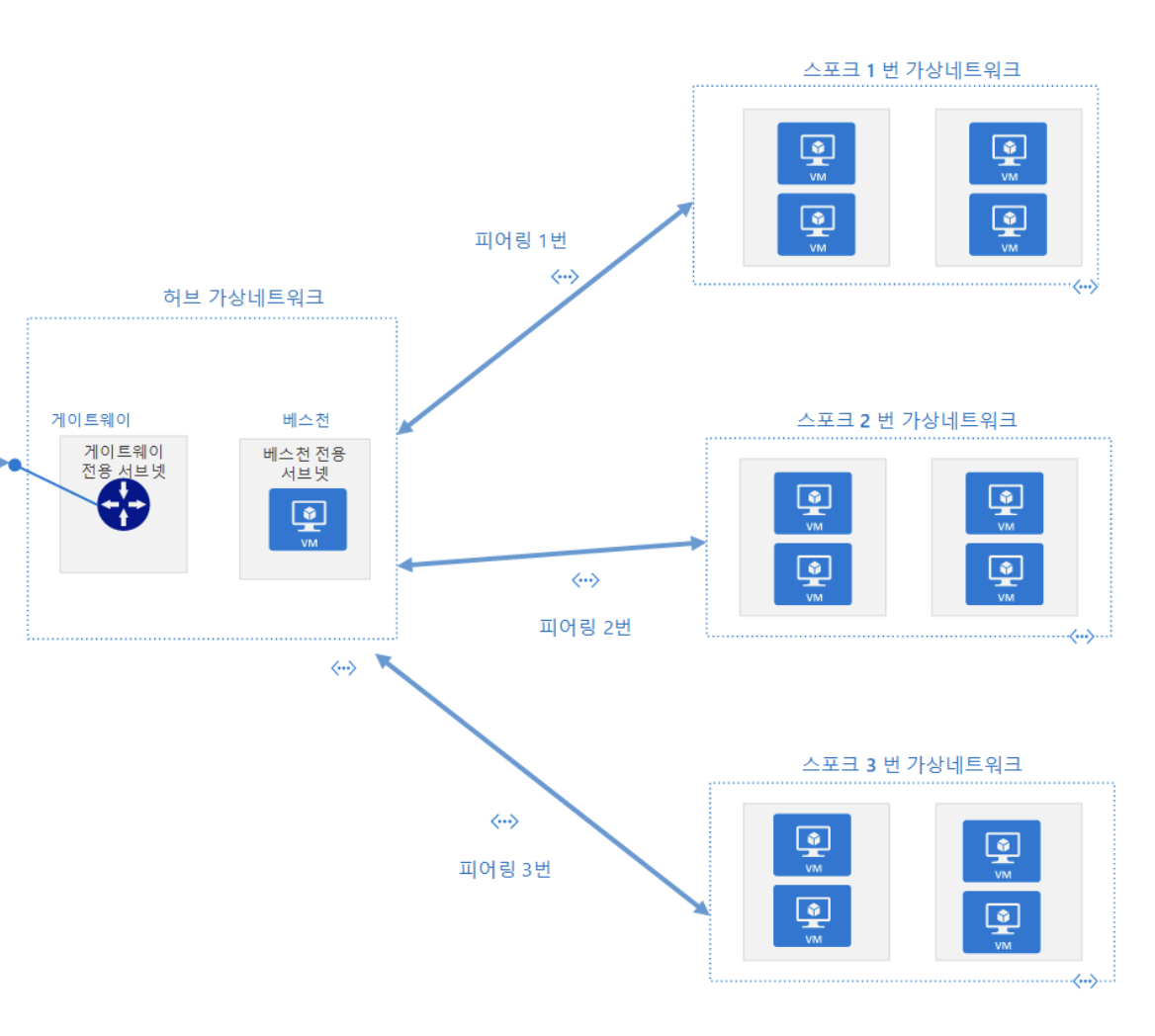
보통의 형태 : 여러 개의 로컬 카프카 클러스터 - 1개의 중앙 카프카 클러스터
단순화된 형태 : 리더와 팔로워 (2개의 클러스터만 사용하는 방식)
데이터가 여러 개의 데이터센터에서 생성되는 반면 일부 컨슈머는 전체 데이터를 사용해야 할 경우 사용됨
각각의 데이터센터에서 실행되는 애플리케이션이 해당 데이터센터의 로컬 데이터만을 사용할 수 있게 해줄 뿐 모든 데이터센터에서 생성된 전체 데이터세트를 사용할 수 있도록 해주지는 않음
아키텍처 구현 시 중앙 데이터센터에 각 지역 데이터센터별로 미러링 프로세스를 최소 한 개 이상 설정해야 하는데, 프로세스는 원격 지역 클러스터의 데이터를 읽어서 중앙 클러스터에 씀
다수의 데이터센터에 같은 이름의 토픽이 존재한다면 이 토픽들의 모든 데이터를 중앙 크러스터와 같은 이름 토픽 안에 쓰거나 아니면 각각의 데이터센터에서 미러링된 이벤트를 서로 다른 토픽에 쓰거나 할 수 있음
장점
항상 로컬 데이터센터에서 데이터가 생성되고, 각각의 데이터센터에서 저장된 이벤트가 중앙 데이터센터로 단 한번만 미러링됨
단일 데이터센터의 데이터를 처리하면 애플리케이션은 해당 데이터센터에 배치될 수 있음
다수의 데이터센터에서 생성된 데이터를 처리하는 애플리케이션은 모든 데이터가 미러링되는 중앙 데이터센터에 두면 됨
미러링은 한 방향으로만 진행되고 각각의 컨슈머는 언제나 같은 클러스터에서 데이터를 읽게 되므로 배포, 설정, 모니터링이 간편함
단점
- 지역 데이터센터에 있는 애플리케이션은 다른 데이터센터에 있는 데이터를 사용할 수 없음
# 액티브-액티브
두 개 이상의 데이터센터가 전체 데이터의 일부 혹은 전체를 공유하면서 각 데이터센터가 모두 읽기와 쓰기를 수행할 수 있어야 할 경우에 사용됨
동일 데이터세트를 여러 위치에서 비동기적으로 읽고 써야 하는 문제를 해결할 방법을 찾고 있다면 이 아키텍처를 권장하는데, 확장성, 회복력, 유연성, 가성비까지 가장 좋은 선택으로 순환 복제를 방지하고 사용자들을 대체로 같은 데이터센터 안에 유지하고 충돌이 발생할 때 처리하는 방법에 대해 신경쓸 필요가 있음
액티브-액티브 미러링 수행 시, 데이터센터의 개수가 2개 이상일 경우 어려움 중 하나는 각 쌍의 데이터센터의 양 방향에 대해 미러링 작업이 필요한데 최근 사용되는 미러링 툴은 프로세스를 공유할 수 있게 됨
같은 데이터 클러스터 사이를 오가면서 끝없이 순환 미러링되는 것을 막아야 하는데, 논리적 토픽에 대해 데이터센터별로 별도의 토픽을 두고 원격 데이터센터에서 생성된 토픽의 복제를 마음으로써 가능함
미러링 툴은 유사한 네이밍 컨벤션을 사용하여 순환 미러링을 방지함
카프카 0.11.0에서 추가된 레코드 헤더 기능은 각각의 이벤트에 데이터가 생성되는 데이터 센터를 태그로 할 수 있도록 하는데, 헤더에 심어진 정보는 이벤트가 무한히 순환 미러링되는 것을 방지하거나 다른 데이터센터에서 미러링된 이벤트를 별도로 처리하는 등의 용도로 사용될 수 있음
레코드 밸류값에 사용되는 구조화된 데이터 형식을 사용하여 이벤트 자체의 헤더에 태그를 심는 식으로 기능을 구현할 수도 있지만 현존하는 미러링 툴이 특별한 헤더 형식을 지원하지 않아 미러링 작업에 추가적인 작업이 필요함
장점
인근 데이터센터에서 사용자들의 요청을 처리할 수 있음
사용할 수 있는 데이터가 제한됨으로써 발생하는 기능 제한이 없으며 성능상으로도 이점이 있음
데이터 중복과 회복 탄력성이 있어 모든 데이터센터가 모든 기능을 동일하게 가지므로 한 데이터센터에 장애가 발생하더라도 사용자 요청을 다른 데이터센터에서 처리할 수 있음
장애 복구는 네트워크 리다이렉션만을 필요로 하고, 보통 가장 쉽고 명료한 형태로 볼 수 있음
단점
데이터를 여러 위치에서 비동기적으로 읽거나 변경할 경우, 발생하는 충돌을 피하기 어려움
이벤트를 미러링하는데 있어서의 기술적인 어려움을 포함함
두 데이터 센터 간의 데이터 일관성을 유지하기 어려움
# 액티브-스탠바이
데이터센터 안에 두 개의 클러스터를 가지고 있는 경우로 모든 애플리케이션이 첫번째 클러스터를 사용할지라도 첫번째 클러스터 안의 거의 모든 데이터를 가지고 있다가 첫번째 클러스터가 완전히 사용할 수 없게 될 경우 대신 사용할 수 있는 두 번째 클러스터가 필요해질 수 있는 상황일 때를 의미함
장점
간단한 설치가 가능하여 대부분의 활용 사례에서 사용될 수 있어 두번째 클러스터를 설치한 뒤 첫번째 클러스터의 모든 이벤트를 미러링하는 프로세스를 설치하기만 하면 됨
데이터 접근, 충돌 처리, 기타 복잡한 아키텍처 문제에 대해 걱정할 필요가 없음
단점
멀쩡한 클러스터를 놀려야 한다는 점이 있음
카프카 클러스터 간의 장애 복구가 보기보다 훨씬 어려워일체의 데이터 유실이 카프카 클러스터를 완벽하게 복구하는 것은 불가능하여 최소화할 수야 있지만 완전히 없앨 수는 없음
재해 상황을 제외하면 대기 상태로만 있는 클러스터는 자원의 낭비로 보이기 때문에 일부 조직에서는 프로덕션 클러스터보다 DR 클러스터를 훨씬 작은 크기로 생성하여 이 문제를 해결하려고 하지만 최소한의 크기로 설정된 클러스터가 비상시에 제대로 작동할 수 있는지 확신할 수 없음
1) 재해 복구 계획
1-1) 복구 시간 목표 (RTO, recovery time objective)
모든 서비스가 장애가 발생한 뒤 다시 작동을 재개할 떄까지의 최대 시간을 가리킴
낮은 수준의 RTO는 자동화된 장애 복구에서만 가능하므로 더 낮은 RTO를 목표로 할 수록 수동 작업과 애플리케이션 재시작을 최소화하는 것이 중요함
1-2) 복구 지점 목표 (RPO, recovery point objective)
장애의 결과로 인해 데이터가 유실될 수 있는 최대 시간을 가리킴
낮은 PRO는 지연 시간이 짧은 실시간 미러링을 필요로 하여 아예 0으로 만들려면 동기적 방식으로 미러링을 수행해야만 함
2) 계획에 없던 장애 복구에서의 데이터 유실과 불일치
DR 클러스터는 주 클러스터의 가장 최신 메시지를 가지고 있지 못하는데 DR 클러스터가 주 클러스터에 뒤쳐져 있는지 항상 모니터링하고 너무 뒤쳐지지 않도록 신경써야 함
사전에 계획된 장애 복구의 경우, 주 클러스터를 먼저 멈춘 뒤 애플리케이션을 DR 클러스터로 마이그레이션하기 전에 미러링 프로세스가 남은 메시지를 모두 미러링할 때까지 기다림으로써 유실을 방지할 수 있음
예상치 못한 장애로 수천 개의 메시지를 유실했을 경우, 미러링 솔루션들이 현재로서는 트랜잭션을 지원하지 않음
3) 장애 복구 이후 애플리케이션의 시작 오프셋
다른 클러스터로 장애 복구할 때 가장 어려운 것은 다른 클러스터로 옮겨간 애플리케이션이 데이터를 읽어오기 시작하는 위치를 결정하는 것으로 몇 가지 흔히 사용되는 방법이 있지만 데이터 유실이나 중복을 초래할 수 있음
3-1) 자동 오프셋 재설정
아파치 카프카 컨슈머는 사전에 커밋된 오프셋이 없을 경우, 어떻게 작동해야 하는지를 결정하는 설정값이 있는데 장애 복구 계획에 이 오프셋을 미러링하는 부분이 빠져있다면 두 가지 옵션 중에서 양자택일 해야 하는데, 데이터의 맨 처음부터 읽기시작해서 상당한 수의 많은 양의 데이터를 처리할 것인지 아니면 맨 끝에서 시작해서 알려지지 않은 개수의 이벤트를 건너뛸 것인지에 대해 애플리케이션이 아무런 이슈없이 중복을 처리할 수 있거나 약간의 유실이 별 문제가 안된다면 선택은 매우 쉬움
장애 복구 중인 토픽의 맨 끝에서부터 읽기 시작하는 것은 단순한 만큼 많이 사용됨
3-2)오프셋 토픽 복제
카프카 0.9버전 이후의 컨슈머에서는 자신의 오프셋을 __consumer_offsets로 불리는 토픽에 커밋하는데 이 토픽을 DR 클러스터로 미러링해준다면 DR 클러스터에서 읽기 작업을 시작하는 컨슈머는 이전에 주 클러스터에 마지막으로 커밋한 오프셋부터 작업을 개재하는데 많은 주의사항이 따름
주의사항
- 주 클러스터의 오프셋이 DR 클러스터의 오프셋과 일치할 것이라는 보장이 없음
- 토픽이 처음 생성된 시점부터 미러링을 시작하여 주 클러스터와 DR 클러스터의 토픽이 모두 0부터 시작할지라도 프로듀서 재시도로 인해 오프셋이 서로 달라질 수 있음
- 오프셋이 완벽히 보존되었다 할지라도 주 클러스터와 DR 클러스터 사이에 랙이 존재한다는 것, 현재 미러링 솔루션이 트랜잭션 기능을 지원하지 않는 다는 사실 때문에 카프카 컨슈머가 커밋한 오프셋이 해당 오프셋을 해당하는 레코드보다 먼저 혹은 늦게 도착할 수 있음
- 장애 복구 중인 컨슈머 입장에서는 커밋된 오프셋이 있는데 정작 해당하는 레코드는 없을 수 있고, DR 클러스터쪽에 마지막으로 커밋된 오프셋이 주 클러스터에 마지막으로 커밋된 오프셋보다 더 오래되었을 수도 있음
- DR 클러스터의 마지막으로 커밋된 오프셋에 해당하는 레코드가 실제로 존재하지 않을 때 어떻게 처리해야 할지도 결정해야 함
3-3) 시간 기반 장애 복구
카프카 0.10.0버전부터 메시지는 카프카로 전송되는 시각을 가리키는 타임스탬프 값을 갖고, 브로커는 타임스탬프를 기준으로 오프셋을 검색할 수 있는 인덱스와 API를 포함함
애플리케이션의 시작 시간을 지정할 수 있는 사용자 설정을 추가하여 애플리케이션은 새로운 API를 사용하여 주어진 시각에 해당하는 오프셋을 가져오고 해당 오프셋으로 이동한 뒤 바로 그 지점에서부터 읽기 작업을 시작하고 오프셋 커밋 역시 이전과 똑같이 하면 됨
카프카 0.11.0부터 추가된 타임스탬프 기준 초기화를 포함하는 다양한 오프셋 초기화를 지원하는 kafka-consumer-groups라는 툴로 실행되는 도중에 컨슈머 그룹은 잠시 작업을 중단했따가 실행이 완료되면 즉시 다시 시작됨
특정 컨슈머 그룹의 모든 토픽에 컨슈머 오프셋을 특정 시점으로 초기화하는 명령어를 실행하여 어느 정도의 확실성을 보장해야 하는 경우에 권장됨
3-4) 오프셋 변환
오프셋 토픽을 미러링할 때 가장 어려운 것은 주 클러스터와 DR 클러스터의 오프셋이 어긋날 수 있다는 점이 있음
미러링 툴은 서로 매핑되는 오프셋 값을 외부 저장소로 전송하여 미러메이커를 포함한 미러링 솔루션들이 오프셋 변환 메타 데이터를 저장하기위해 카프카 토픽을 사용하는데 오프셋 매핑은 양쪽의 오프셋 값 차이가 달라질 때마다 저장됨
실제 장애 복구 작업을 수행하면 타임스탬프 기준으로 오프셋을 변환하는 대신 주 클러스터 오프셋에 매핑되는 DR 클러스터 오프셋을 찾아서 작업을 재개하면 되는데 컨슈머가 저장된 매핑으로부터 가져온 새로운 오프셋을 사용하여 작ㅇ버을 시작하도록 할 때 두 방식 중 하나를 선택하여 작업을 할 수 있고, 이 방식은 커밋된 오프셋이 레코드보다 먼저 미러링되거나 커밋된 오프셋이 제 시간에 맞춰 DR 클러스터로 미러링되지 않을 경우 여전히 문제가 있지만 어떠한 경우에는 적절한 방식이 될 수 있음
4) 장애 복구가 끝난 후
DR 클러스터에서 모든 것이 잘 작동하고 있을 단계로, 주 클러스터에 해줘야 하는 작업이 있음
장애가 생겼던 주 클러스터를 DR 클러스터로 역할을 변경해야 함
어디서부터 미러링을 시작해야 할지에 대해 컨슈머에 대해서 다뤘던 것과 동일한 문제를 미러링 애플리케이션 그 자체에 대해 해결해야 하는데 해법을 찾건 같에 중복이 발생하거나 유실이 발생하거나 둘다 발생할 수 있다는 점을 명심해야 함
이전 주 클러스터는 DR 클러스터가 가지고 있지 않은 이벤트를 가지고 있을 가능성이 높으므로 새로운 데이터를 반대 방향으로 미러링하기 시작한다면 이 여분의 이벤트들은 여전히 이전 주 클러스터 안에 남아 있을 것이고 두 클러스터의 내용물은 서로 달라짐
일관성와 순서 보장이 극도로 중요한 상황에서 가장 간단한 해법은 원래 주 클러스터에 저장된 데이터와 커밋된 오프셋을 완전히 삭제한 뒤 새로운 주 클러스터에서 완전히 새것이 된 새 DR 클러스터로 미러링을 시작하여 새 주 클러스터와 완전히 동일한 깨끗한 상태의 DR 클러스터를 얻을 수 있음
5) 클러스터 디스커버리 관련
장애가 발생하는 상황에서 애플리케이션이 장애 복구용 클러스터와 통신을 시작하는 방법을 알 수 있게 해야 함
호스트 이름을 하드코딩하지 않고 호스트 이름을 최대한 단순하게 정한 뒤 DNS를 써서 주 클러스터 브로커로 연결하여 비상상황이 닥치면 DNS 이름을 스탠바이 클러스터로 돌리면 됨
디스커버리 서비스가 모든 브로커에 대한 IP 주소를 가진 필요가 없는데, 카프카 클라이언트는 클러스터 메타데이터를 얻어와서 다른 브로커의 위치를 찾기 위해 하나의 브로커에만 성고적으로 접근할 수 있어 대체로 3개의 브로커 정보만 가지고 있으면 됨
디스커버리 서비스가 어떠한 것이든 간에 대부분의 장애 복구 상황에서 장애 발생 후 컨슈머 애플리케이션이 작업을 재개할 새 오프셋을 잡아 주어야 하는데, RTO를 극도로 낮추기 위해 애플리케이션 재시작 없는 완전히 자동화된 장애 복구를 수행하고자 한다면 장애 복구 로직이 클라이언트 애플리케이션에 내장되어 있어야 함
# 스트레치 클러스터
액티브-스탠바이 아키텍처
카프카 클러스터에 장애가 발생했을 때 애플리케이션이 다른 클러스터와 통신함으로써 전체 업무가 마비되는 것을 방지하기 위해 사용됨
스트레치 클러스터
데이터센터 전체에 문제가 발생했을 때 카프카 클러스터에 장애가 발생하는 것을 방지하기 위한 것으로 하나의 카프카 클러스터를 여러 개의 데이터센터에 걸쳐 설치함
다중 데이터센터를 상정한 다른 방식과는 본질적으로 다른데 스트레치 클러스터는 다중 클러스터가 아닌 하나의 클러스터로 두 클러스터를 동기화시켜주는 미러링 프로세스가 필요 없음
카프카의 복제 메커니즘이 평소대로 클러스터 안의 브로커들을 도익화된 상태로 유지시켜주므로, 동기적인 복제를 포함함
프로듀서는 메시지가 카프카에 성공적으로 쓰여진 다음 브로커로부터 응답을 받는데, 스트레치 클러스터는 메시지가 두 데이터센터에 위치한 카프카 브로커 각각에게 성공적으로 쓰여진 뒤에야 응답이 가도록 설치될 수 있음
각 파티션이 하나 이상의 데이터센터에 분산해서 레플리카를 저장하도록 랙 설정을 정의하고 min.insync.replicas 설정을하고, acks 설정을 all로 잡아줌으로써 각가의 쓰기 작업이 최소 두 개의 데이터센터에서 성공한 다음에야 응답이 가도록 해주면 됨
2.4.0부터 컨슈머가 정의된 랙 기준으로 가장 가까운 레플리카에서 읽어올 수 있도록 브로커를 설정할 수 있는데 이 기능을 사용하면 브로커는 컨슈머의 랙 설정과 자신의 랙 설정을 맞춰 본 뒤 로컬 레플리카가 최신 상태를 가지고 있는지 확인한 뒤 그게 아니면 리더에게 처리를 넘기게 되고, 컨슈머는 로컬 데이터센터에 위치한 팔로워로부터 데이터를 읽어 처리율을 높이고 지연은 낮추고 데이터센터 간 통신을 줄임으로써 비용을 낮춤
카프카를 높은 대역폭과 낮은 지연을 가진 회선으로 서로 연결된 최소 3개의 데이터센터에 설치할 경우에 적합한데, 서로 인접한 주소에 3개의 건물을 가진 회사에서 일하고 있거나 좀 더 일반적으로 클라우드 제공자의 한 리전 안에 3개의 가용 영역을 사용중이라면 이것이 가능함
3개의 데이터센터라는 조건이 중요한 이유는 주키퍼 클러스터 때문으로 홀수 개의 노드로 이루어지기 때문에 노드 중 과반 이상만 작동하면 전체 클러스터 역시 작동에 이상이 없음
데이터센터가 3개 있다면 어느 데이터센터에도 과반 이상의 노드가 몰리지 않도록 배치하는 것이 쉬운데 하나의 데이터센터에 문제가 발생한다고 해도 나머지 두 데이터센터에 배치된 과반 이상의 노드들은 작동에 지장이 없고, 주키퍼 클러스터 역시 장애가 발생하지 않음(카프카 클러스터도 마찬가지)
주키퍼 그룹 기능을 사용하면 두 개의 데이터센터에서 주키퍼와 카프카를 실행할 수 있어 두 개의 데이터센터 간에 수동으로 재해 복구가 가능하지만 흔하지 않음
장점
동기적인 복제로, DR 클러스터가 주 클러스터와 언제나 100% 동기화되어 있어야만 하는 경우도 있어 때때로 벅접 요구조건인 경우 카프카를 포함함 회사에서 사용 중인 모든 데이터 저장소에 해동됨
양 데이터 센터와 클러스터 안의 모든 브로커가 사용되므로 액티브-스탠바이 아키텍처에서 살펴봤던 유형의 자원 낭비가 전혀 없음
단점
장애 종류가 한정되어 데이터센터 전체에 장애가 난 경우 대응할 수 있지만 애플리케이션이나 카프카에 장애가 발생하는 경우 커버하지 않음
복잡한 설정도 제한되어 물리적인 인프라스트럭처를 필요로 하지만 모든 회사들이 이걸 가지고 있지 않음
# 아파치 카프카 미러메이커
미러메이커 2.0은 아파치 카프카를 위한 차세대다중 클러스터 미러링 솔루션으로 카프카 커넥트 프레임워크에 기반하여 개발되었고 이전 버전의 여러 단점들을 해결하고 있음
재해 복구, 백업, 마이그레이션, 데이터 집적 등 넓은 범위의 활용 사례를 지원할 수 있도록 복잡한 토폴리지를 쉽게 설정할 수 있음
미러케이커는 데이터베이스가 아닌 다른 카프카 클러스터로부터 데이터를 읽어오기 위해 소스 커넥트를 사용함
미러메이커에서는 각 태스크를 필요에 따라 서로 다른 커넥터 워커 노드로 할당하여 여러 태스크를 하나의 서버에서 수행할 수도 있고 여러 개의 서버에서 나눠서 수행할 수 있어 인스턴스별로 몇 개의 미러메이커 스트림을 실행시켜야 하는지, 서버별로 몇 개의 인스턴스를 실행시켜야 하는지를 직접 결정하는 작업을 자동화해줌
커넥트는 커넥터와 태스크 설정을 한 곳에서 관리할 수 있는 REST API를 제공함
미러메이커는 카프카의 컨슈머 그룹 관리 프로토콜을 사용하지 않고 태스크에 파티션을 균등하게 배분함으로써 새로운 토픽이나 파티션이 추가되었을 때 발생하는 리밸런스로 인해 대상 클러스터의 동일한 파티션으로 미러링함으로써 파티션의 의미 구조나 각 파티션 안에서의 이벤트 순서를 그대로 유지하고, 원본 토픽에 새 파티션이 추가될 경우 자동으로 대상 토픽을 생성함
미러메이커는 데이터 복제 뿐만 아니라 컨슈머 오프셋, 토픽 설정, 토픽 ACL 마이그레이션까지 지원하기에 자동 클러스터 배치에 필요한 오나전한 기능을 갖춘 미러링 솔루션을 말함
# 미러메이커 설정
미러메이커
- 토폴로지, 카프카 커넥트, 커넥터 설정을 정의하기 위한 클러스터 설정 뿐만 아니라 미러메이커가 내부적으로 사용하는 프로듀서, 컨슈머, 어드민 클라이언트의 모든 설정 매개변수도 커스터마이징이 가능함
미러메이커 실행
- properties 파일에 정의된 설정값을 사용하여 미러메이커를 실행시킴
| |
미러메이커 옵션
1. 복제 흐름
| |
2. 미러링 토픽
미러링될 토픽을 지정하기 위해 정규식을 사용하는데, 테스트 토픽이 복제 되지 않도록 해주어야 함
미러링에서 제외할 토픽 목록이나 패턴을 별도로 지정할 수도 있음
복제된 대상 토픽명 앞에는 기본적으로 원본 클러스터의 별칭이 접두어로 붙음
기본 네이밍 전략은 액티브-액티브 모드에서 두 클러스터 간에 메시지가 무한히 순한 복제되는 사태를 방지함
로컬 토픽과 원격 토픽을 구분해줄 경우 컨슈머 구독 패턴 기능을 사용하여 로컬 리전의 토픽만 구독하거나 아니면 전체 데이터세트의 내용을 볼 수 있도록 전 리전의 토픽을 구독하는 것 중에 선택하도록 할 수 있음
미러메이커는 원본 클러스터에 새로운 토픽이 추가되었는지 주기적으로 확인하고 설정된 패턴과 일치할 경우 자동으로 이 토픽들에 대한 미러링 작업을 시작하는데, 원본 토픽에 파티션이 추가될 경우 대상 토픽에도 자동으로 추가되므로 원본 토픽의 이벤트가 대상 토픽에서도 같은 파티션 같은 순서로 저장되게 됨
3. 컨슈머 오프셋 마이그레이션
미러메이커는 주 클러스터에서 DR 클러스터로 장애 복구를 수행할 때 주 클러스터에서 마지막으로 체크포인트된 오프셋을 DR 클러스터에서 찾을 수 있도록 RemoteClusterUtils 유틸리티 클래스를 포함함
주 클러스터에 커밋된 오프셋을 자동으로 변환하여 DR 클러스터의
__consumer_offsets에 커밋해줌으로써 DR 클러스터로 옮겨가는 컨슈머들이 별도의 마이그레이션 작업 없이도 주 클러스터의 커밋 지점에 해당하는 오프셋에서 바로 작업을 재개할 수 있게 해주어 마이그레이션할 컨슈머 그룹의 목록 역시 커스터마이징이 가능한데 예상치 못한 사고를 방지하기 위해 현재 대상 클러스터 쪽 컨슈머 그룹을 사용중인 컨슈머들이 있을 경우 미러메이커는 오프셋을 덮어쓰지 않아 현재 작동 중인 컨슈머들의 컨슈머 그룹 오프셋과 원본에서 마이그레이션된 오프셋이 충돌하는 사태는 발생하지 않음
4. 토픽 설정 및 ACL 마이그레이션
데이터 레코드를 미러링하는 것 외에도 토픽 설정과 접근 제어 목록을 미러링하도록 설정할 수 있음
기본 설정값을 그대로 두면 일정한 주기로 ACL을 마이그레이션 해주고, 대부분의 원본 토픽 설정값은 대상 토픽에 그대로 적용되지만 min.insync.replicas 같은 몇 개는 예외이고, 동기화에서 제외되는 설정의 목록 역시 커스터마이즈가 가능함
미러링되는 토픽에 해당하는 Literal 타입 ACL만이 이전되므로 자원 이름에 접두어 혹은 와일드카드(
*)를 사용하거나 다른 인가 매커니즘을 사용하고 있을 경우 대상 클러스터에 명시적으로 설정을 잡아줘야 함미러메이커만이 대상 토픽에 쓸 수 있도록 하기 위해 Topic:Write ACL 역시 이전되지 않음
장애 복구를 위한 애플리케이션이 대상 클러스터에 읽거나 쓸 수 있도록 하기 위해 적절한 접근 권한을 명시적으로 잡아주어야 함
5. 커넥터 태스크
tasks.max 설정 옵션은 미러메이커가 띄울 수 있는 커넥터 태스크의 최대 개수를 정의함
기본값은 1로, 최소 2이상으로 올려줄 것을 권장하며 복제해야 할 토픽 파티션의 수가 많다면 병렬 처리의 수준을 올리기 위해 가능한 한 더 큰 값을 사용해야 함
6. 설정 접두어
미러메이커에 사용되는 모든 컴포넌트(커넥터, 프로듀서, 컨슈머, 어드민 클라이언트)에 대해서 설정 옵션을 잡아줄 수 있는데, 카프카 커넥트와 커넥터 설정은 별도의 접두어를 필요로 하지 않음
미러메이커에는 2개 이상의 클러스터에 대한 설정이 포함될 수 있어 특정 클러스터나 복제 흐름에 적용되는 설정의 경우 접두어를 사용할 수 있음
클러스터를 구분할 때 사용되는 별칭은 해당 클러스터에 관련된 설정값을 잡아줄 때 접두어로 사용되는데 설정에는 계층 구조가 적용되고 더 구체적인 접두어를 갖는 설정이 접두어가 없거나 덜 구체적인 접두어가 붙은 설정에 비해 더 우선권을 갖음
{클러스터}.{커넥터 설정}{클러스터}.admin.{어드민 클라이언트 설정}{원본 클러스터}.consumer.{컨슈머 설정}{대상 클러스터}.producer.{프로듀서 설정}{원본 클러스터}-}{대상클러스터}.{복제 흐름 설정}
# 다중 클러스터 토폴로지
액티브-액티브 토폴로지는 단순히 양방향 복제 흐름을 활성화하는 것만으로 설정이 가능함
미러메이커는 원격 토픽 앞에 클러스터 별칭을 붙임으로써 동일한 이벤트가 순환 복제되는 것을 방지함
여러 개의 미러메이커 프로세스를 실행시킬 때 전체 복제 토폴로지를 기술하는 공통 설정 파일을 사용하는 것이 좋은데 설정이 대상 데이터센터의 내부 토픽을 통해 공유될 때 발생하는 충돌을 방지할 수 있음
미러메이커 프로세스를 시작할 때 –clusters 옵션을 사용하여 대상 클러스터를 지정함으로써 공유 설정을 사용하는 미러메이커 프로세스를 대상 클러스터 안에서 실행시킬 수 있음
| |
- 토폴로지에는 추가적인 원본 / 대상 클러스터를 갖는 복제 흐름을 추가 정의할 수 있음
| |
# 미러메이커 보안
미러메이커의 경우 원본과 대상 클러스터 양쪽에 대해 보안이 적용된 브로커 리스너를 사용하도록 설정되어야 하며, 각 클러스터에 대해 클라이언트 쪽 보안 옵션들 역시 설정되어야 함
모든 데이터센터 간 트래픽에는 SSL 암호화가 적용되어야 함
| |
- 클러스터에 인가가 설정되어 있을 경우, 미러메이커에 적용되는 자격 증명에는 원본과 대상 클러스터에 적절한 권한이 부여되어야 함
미러메이커 프로세스 ACL 부여
원본을 읽어오기 위한 원본 클러스터의 Topic:Read 권한, 대상 클러스터에 토픽을 생성하고 메시지를 쓰기 위한 대상 클러스터의 Topic:Create, Topic:Write 권한, 원본 토픽의 설정을 얻어오기 위한 클러스터의 Topic:DescribeConfigs 권한, 대상 토픽 설정을 업데이트하기 위한 대상 클러스터의 Topic:AlterConfigs 권한
새로운 원본 파티션이 탐지되었을 때 토픽을 추가해주기 위한 대상 클러스터의 Topic:Alter 권한
오프셋을 포함한 원본 컨슈머 그룹 메타데이터를 얻어오기 위한 원본 클러스터의 Group:Describe 권한, 커늇머 그룹의 오프셋을 대상 클러스터 쪽에 커밋해주기 위한 대상 클러스터의 Group:Read 권한
원본 토픽의 ACL을 가져오기 위한 원본 클러스터의 Cluster:Describe 권한, 대사 토픽의 ACL을 업데이트하기 위한 대상 클러스터의 Cluster:Alter 권한
미러메이커 내부 토픽에 사용하기 위한, 원본과 대상 클러스터 모두의 Topic:Create, Topic:Wrtie 권한
# 운영 환경에 배포
미러메이커는 도커 컨테이너 안에서도 실행할 수 있는데 이는 상태가 없어 디스크 공간을 아예 필요로 하지 않음
미러메이커가 카프카 커넥터에 기반한 만큼 카프카 커넥트에서 미러메이커를 실행시킬 수 있는데 개발이나 테스트 용도라면 독립 실행 모드로 작동시킬 수 있음
미러메이커는 별도로 설치된 분산 모드 카프카 커넥트 클러스터에서 커넥터 형태로도 실행될 수 있음
프로덕션 환경에서 사용한다면 미러메이커를 분산 모드로 실행시킬 것을 권장함
미러메이커는 가능한 한 대상 데이터센터에서 실행시키는 것이 좋은데, 장거리 네트워크는 데이터센터 내 네트워크에 비해 약간 더 불안정할 수 있으므로 네트워크 단절이 일어나서 데이터센터 간 연결이 끊어질 경우 컨슈머가 클러스터에 연결할 수 없는 편이 프로듀서가 연결할 수 없는 편보다 훨씬 더 안전함
지역 읽기-원격 쓰기를 해야하는 경우에는 컨슈머는 더 이상 제로카피 최적화의 이득을 볼 수 없어 성능 타격은 카프카 브로커 그 자체에도 영향을 미치므로 데이터센터간 트래픽에는 암호화가 필요한데 지역 트래픽은 그렇지 않다면 암호화되지 않은 데이터를 같은 데이터센터 내에서 읽어서 SSL 암호화된 연결을 통해 원격 데이터센터쪽으로 쓰도록 미러메이커를 원본 쪽 데이터센터에 놓는게 나은데 이 경우 프로듀서 쪽은 SSL을 통해 카프카에 연결하지만 컨슈머 쪽은 그렇지 않으므로 성능에 큰 영향을 주지 않음
미러메이커가 문제가 발생했을 때 빠르게 실패하도록 errors.tolerance=none 설정을 잡아주면 이벤트 전송에 실패했을 때는 그냥 에러가 발생하는 쪽이 데이터 유실의 위험을 안고 작업을 계속하는 쪽보다 나음
최신 자바 버전에는 SSL 성능이 비약적으로 향상되어 암호화를 수반하는 지역 읽기-원격 쓰기는 실행 가능한 옵션일 수 있음
지역 읽기-원격 쓰기를 해야하는 상황은 하이브리드 환경으로 온프레미스 클러스터의 토픽을 클라우드 클러스터로 미러링하는 것인데 안전한 온프레미스 클러스터는 클라우드로부터의 연결을 허용하지 않는 방화벽 뒤에 설정되어 있을 가능성이 높고 미러메이커를 온프레미스 쪽에서 작동시키면 모든 연결은 온프레미스에서 클라우드 방향으로 맺어지도록 할 수 있음
1) 미러메이커를 프로덕션 환경에 배포할 때 모니터링해야 하는 영역
1-1) 카프카 커넥트 모니터링
카프카 커넥트는 커넥터 상태를 모니터링하기 위한 커넥터 지표, 처리량을 모니터링하기 위한 소스 커넥터 지표, 리밸런스 지연을 모니터링하기 위한 워커 지표와 같이 서로 다른 측면을 모니터링하기 위한 넓은 범위의 지표들을 제공함
커넥트는 커넥터들을 확인하고 관리할 수 있는 REST API 역시 제공함
1-2) 미러메이커 지표 모니터링
미러메이커는 미러링 처리량과 복제 지연을 모니터링할 수 있는 지표들을 추가로 제공함
복제 지연 지표인 replication-latency-ms는 레코드의 타임스탬프와 대상 클러스터에 성공적으로 쓰여진 시각 사이의 간격을 보여주는데 대상 클러스터가 원본 클러스터를 제대로 따라오지 못한 상황을 탐지하고자 할 때 도움이 됨
충분한 처리 용량이 있다면 피크 시간대에 지연값이 치솟아도 나중에 따라잡을 수 있어 괜찮지만 이 값이 지속적으로 증가하는 것은 처리 용량이 부족하다는 의미일 수 있음
| 항목 | 설명 |
| record-age-ms | 복제 시점에 레코드가 얼마나 오래되었는지를 보여줌 |
| byte-rate | 복제 처리량을 보여줌 |
| checkpoint-latency-ms | 오프셋 마이그레션의지연을 보여줌 |
- 미러메이커 역시 주기적으로 하트비트를 보내는 것이 기본 설정으로 이를 사용하면 미러메이커의 상태를 모니터링할 수 있음
1-3) 랙을 추적하는 방법
미러메이커가 원본 카프카 클러스터에 마지막으로 커밋된 오프셋을 추적하는데, kafka-consumer-groups 툴을 사용하여 미러메이커가 현재 읽고 있는 각 파티션을 확인할 수 있어 파티션의 마지막 이벤트 오프셋, 미러메이커가 커밋한 마지막 오프셋, 둘 사이의 랙을 볼 수 있음
미러메이커가 항상 오프셋을 커밋하는 것은 아니므로 100%로 정확하지 않지만 기본 설정값이 1분에 한번 커밋하도록 잡혀 있어 1분 동안은 이 값이 늘어나다가 갑자기 낮아지는 것을 볼 수 있음
커밋여부와 상관ㅇ벗이 미러메이커가 읽어 온 최신 오프셋을 추적하는데 미러메이커에 포함되어 있는 컨슈머들은 핵심 지표들을 JMX의 형태로 내보내는데 이들 중 하나가 현재 읽고 있는 파티션들에 대한 랙 최대값을 보여주는 최대 컨슈머 렉으로 이 값 역시 100% 정확한 것은 아님
컨슈머가 읽어온 메시지를 기준으로 업데이트될 뿐 프로듀서가 해당 메시지를 대상 카프카 클러스터에 썼는지 그리고 응답을 받았는지의 여부는 전혀 고려하지 않음
1-4) 프로듀서/컨슈머 지표 모니터링
미러메이커가 사용하는 카프카 커넥트 프레임워크는 프로듀서와 컨슈머를 포함하여 여러 지표들을 모니터링 가능한 형태로 제공하고 이들을 수집하고 추적할 것을 권장함
| 컨슈머 | fetch-size-avg, fetch-size-max, fetch-rate, fetch-throttle-time-avg, fetch-throttle-time-max |
| 프로듀서 | batch-size-avg, batch-size-max, requests-in-flight, record-retry-rate |
| 둘다 | io-ratio, io-wait-ratio |
1-5) 카나리아 테스트
1분에 한 번 소스 클러스터의 특정한 토픽에 이벤트를 하나 보낸 뒤 대상 클러스터의 토픽에서 해당 메시지를 읽는 식으로 구현하면 되는데 이렇게 하면 이벤트가 복제될 때까지 걸리는 시간이 일정 수준을 넘어갔을 때 정보를 받을 수 있는데 이런 상황이 발생한다면 미러메이커가 랙에 시달리고 있거나 아니면 아예 작동 중이지 않은 상태를 의미함
# 미러메이커 튜닝
미러메이커는 수평 확장이 가능하며 클러스터 크기는 필요한 처리량과 허용할 수 있는 랙의 크기에 의해 결정됨
랙을 사용할 수 없다면 최고 수준의 처리량을 유지하도록 미러메이커의 크기를 키워야 하고, 어느 정도의 랙을 허용할 수 있다면 미러메이커가 전체 시간의 95~99%에 대해 75~80% 정도의 사용률을 보이도록 할 수 있어 피크 시간대에 어느 정도 랙이 발생할 수 있다고 생각하면 됨
kafka-performance-producer 툴을 사용하여 태스크를 실행시켜 성능이 줄어드는 시점에 대해 tasks.max 설정값을 그보다 살짝 아래 잡아주면 됨
미러메이커는 압축된 이벤트를 읽거나 쓰고 있을 경우, 이벤트의 압축을 해제한 뒤 재압축해야 하는데 CPU를 매우 많이 사용하므로 태스크 수를 늘릴 때는 CPU 사용률에 유의해야 함
민감한 토픽들을 별도의 미러메이커 클러스터로 분리하여 토픽의 미러링이 밀리거나 가장 중요한 데이터 파이프라인의 작업이 지연됨으로써 통제할 수 없는 프로듀서가 느려지는 사태를 방지할 수 있음
1) 리눅스 네트워크 설정 최적화 필요
서로 다른 데이터센터 사이에 미러메이커를 돌리고 있을 때 TCP 스택을 튜닝해주는 것이 실질 대역폭을 증가시키는데 도움이 되는데 브로커의 socket.send.buffer.bytes, socket.receive.buffer.bytes 설정을 잡아주어 브로커 쪽 버퍼 크기를 설정할 수 있는데 이러한 설정 옵션들을 잡아줄 때 리눅스 네트워크 설정 최적화도 필요함
TCP 버퍼 크기를 늘림(net.core.rmem_default, net.core.rmem_max, net.core.wmem_default, net.core.wmem_max, net.core.optmem_max)
자동 윈도우 스케일링을 설정(sysctl -w net.ipv4.tcp_window_scaling=1 혹은 /etc/sysctl.conf 파일에 net.ipv4.tcp_window_scaling=1을 추가해줌
TCP 슬로우 스타트 시간을 줄임(/proc/sys/net/ipv4/tcp_slow_start_after_idle 설정값을 0으로 잡아줌)
2) 미러메이커가 사용하는 프로듀서나 컨슈머 튜닝
병목 지점부터 확인하는데, 모니터링하고 있는 프로듀서나 컨슈머의 지표를 확인하여 어느 한쪽은 최대 용량으로 돌아가지만 어느 한쪽이 놀고 있다면 어느쪽을 튜닝해주어야 하는지 명백함
jstack을 사용하여 스레드 덤프를 몇 개 뜬 다음 미러메이커 스레드가 대부분의 시간을 쓰고 있는 지점이 poll인지 send인지를 확인함(전자쪽이라면 대개 컨슈머가 병목, 후자쪽이라면 프로듀서가 병목)
3) 프로듀서 튜닝시 설정 조정
3-1) linger.ms, batch.size
프로듀서가 계속해서 부분적으로 빈 배치들을 전송한다면 약간의 지연을 추가하여 처리량을 증대시킬 수 있음
linger.ms 설정값을 올려잡아 주면 프로듀서는 배치를 전송하기 전 배치가 다 찰때까지 몇 밀리초 동안 대기함
꽉 찬 배치가 전송되고 있는데 메모리에는 여유가 있다면 batch.size 설정값을 올려잡아줌으로써 더 큰 배치를 전송하도록 할 수 있음
3-2) max.in.flight.reqeusts.per.connection
프로듀서가 요청을 전송할 때마다 대상 클러스터로부터 응답이 오기 전까지는 다음 메시지를 보낼 수 없는데 특히 브로커가 메시지에 대해 응답을 보내기 전 상당한 지연이 있는 경우 처리량을 제한할 수 있음
메시지 순서가 중요하지 않다면 max.in.flight.requests.per.connection 설정이 기본값인 5를 사용하는 것이 처리량을 확연히 증가시키는 방법일 수 있음
4) 컨슈머 튜닝 시 설정 조정
4-1) fetch.max.bytes
fetch-size-avg, fetch-size-max 지표가 fetch.max.bytes 설정값과 비슷하게 나온다면 컨슈머는 브로커로부터 최대한의 데이터를 읽어오는 것으로 메모리가 충분하다면 컨슈머가 각 요청마다 더 많은 데이터를 읽어올 수 있도록 fetch.max.bytes 설정값을 올려잡으면 됨
4-2) fetch.min.bytes, fetch.max.wait.ms
컨슈머의 fetch-rate 지표가 높게 유지된다면 컨슈머가 브로커에게 너무 많은 요청을 보내고 있는데 정작 각 요청에서 실제로 받은 데이터는 너무 작은 것을 의미하므로 fetch.min.bytes와 fetch.max.wait.ms 설정을 늘려 잠으면 컨슈머는 요청을 보낼 때마다 더 많은 데이터를 받게 될 것이므로 브로커는 컨슈머 요청에 응답하기 전 충분한 데이터가 쌓일 때까지 기다리게 됨
# 기타 클러스터간 미러링 솔루션
# 우버 uReplicator
인스턴스에 할당된 토픽 목록과 파티션들을 관리하는 중앙집중화된 컨트롤러를 구현하기 위해 Apache Helix를 사용하기로 함
운영자가 REST API를 사용하여 Helix에 저장되는 토픽 목록에 새로운 토픽을 추가하면 uReplicator가 서로 다른 컨슈머들에게 파티션을 할당해주고, 우버는 미러메이커에 사용되는 카프카 컨슈머를 우버 개발자들이 개발한 카프카 컨슈머로 교체함
Helix 컨슈머는 리밸런스를 회피할 수 있고 대신 Helix에서 주어지는 할당 파티션 변경을 받아서 처리함
# 링크드인 브루클린
카프카를 포함한 서로 다른 종류의 데이터 저장소 사이에 데이터를 스트리밍해 줄 수 있는 분산 서비스로, 데이터 파이프라인을 구축하기 위해 사용될 수 있는 범용 데이터 수집 프레임워크를 말함
높은 신뢰성을 갖도록 설계된 확장성 있는 분산 시스템으로 대규모의 카프카 클러스터에서 검증됨
하루에 조 단위의 메시지를 미러링 하는데 사용되고, 안정성, 성능, 운영성 모두에 최적화됨
다수의 데이터 파이프라인을 처리하기 위해 공유해서 사용할 수 있는 서비스로 다수의 카프카 클러스터 간에 데이터를 미러링하기 위해 사용함
관리 작업을 위해 REST API를 제공함
활용 사례
서로 다른 데이터 저장소와 스트림 처리 시스템 사이를 연결해서 데이터를 주고 받게 해줌
서로 다른 데이터 저장소에 대해 CDC 이벤틀르 스트리밍해줌
클러스터 간 카프카 미러링을 제공함
# 컨플루언트의 솔루션
카프카 커넥트 프레임워크에 기반하여 개발됨
운영을 단순화하고 목표 복구 시간과 목표 복구 시점을 낮게 유지하기 위해 스트레치 클러스터를 사용하는 고객들을 위해 컨플루언트는 컨플루언트 플랫폼의 제품의 제품 컴포넌트 중 하나인 컨플루언트 서버에 멀티 리전 클러스터의 기능을 기본으로 탑재함
MRC는 지연과 처리량에 미치는 영향을 최소화하기 위해 비동기적으로 복제되는 레플리카를 사용하여 카프카의 스트레치 클러스터 기능을 개선함
지연이 50밀리초 미만인 가용 영역이나 리전 사이의 복제에 적절하고 클라이언트 복구가 투명하게 이루어지는 장점이 있으며, 안정성이 더 떨어지는 네트워크를 사용하여 연결된, 서로 멀리 떨어진 서버들로 구축된 클러스터를 위해서 좀 더 최근에 컨플루언트 서버에 클러스터 링킹으로 불리는 기능이 탑재되어 클러스터 간 데이터 미러링을 위해 카프카의 클러스터 간 복제 프로토콜의 오프셋 보존 기능을 확장함
1) 컨플루언트 리프리케이터
카프카 커넥트 프레임워크에 기반한 미러링 툴을 말함
서로 다른 토폴로지에 대한 데이터 복제와 컨슈머 오프셋, 토픽 설정 마이그레이션을 지원함
ACL을 마이그레이션하지 않고 자바 클라이언트에 대해서만 오프셋 변환 기능을 지원함
미러메이커와 같은 로컬, 원격 토픽과 같은 개념이 없는 대신 직접 토픽이라는 개념이 있음
미러메이커와 유사하게 리프리케이터 역시 순환 복제를 피하려하지만 레코드 헤더에 출처를 기입하는 방식으로 구현함
복제 랙과 같은 다양한 지표값을 제공하고 REST API나 컨트롤 센터 UI를 사용하여 모니터링할 수도 있고 클러스터간 스키마 마이그레이션과 변환 역시 가능함
2) 멀티 리전 클러스터
데이터센터 간 지연이 50밀리초 이하인 경우에만 적절하지만 동기적인 복제와 비동기적 복제를 조합함으로써 프로듀서 성능에 미치는 영향을 제한하고 더 높은 네트워크 내고성을 제공함
컨플루언트 서버는 ISR 목록에 추가되지 않은 채 비동기적으로 데이터를 복제하는 레플리카인 옵저버의 개념을 도입하였음
사용자는 낮은 지연과 높은 지속성을 모두 잡기 위해 같은 리전 안에서는 동기적 복제를 서로 다른 리전 안에서는 비동기적 복제를 사용할 수 있음
컨플루언트 서버의 레플리카 위치 제한 기능은 랙 ID 설정값을 사용하여 레플리카들이 서로 다른 리전에 분리되도록 하여 지속성을 보장함
컨플루언트 플랫폼 6.1은 자동 옵저버 승격 기능을 지원하여 이 기능을 사용하면 사전에 설정된 조건을 만족할 때 자동으로 옵저버 레프리카가 생성되는데, min.insync.replicas 설정값이 사전 설정된 동기적으로 복제되는 레플리카 수 아래로 나려갈 경우 최신 상태로 동기화중인 옵저버가 자동으로 승격되어 ISR에 추가되게 할 수 있어 ISR 수가 필요한 최소값 이상으로 유지되도록 하여 승격된 옵저버는 동기적으로 복제를 수행하는 만큼 처리량에 영향을 줄 수 있지만 해당 리전에 장애가 발생하더라도 클러스터는 데이터 유실 없이 운영에 필요한 처리량은 유지할 수 있음
장애가 발생한 리전이 복구되면 옵저버들 역시 자동으로 승급이 해체되므로 클러스터는 정상 상태에서의 성능으로 되돌아감
3) 클러스터 링킹
클러스터간 복제 기능을 아예 컨플루언트 서버에 탑재한 것을 말함
클러스터 내 브로커 간 복제와 동일한 프로토콜을 사용하여 서로 다른 클러스터 간에 오프셋을 보존한 채로 복제를 수행하여 오프셋 변환 기능 같은 것을 쓰지 않고 클라이언트를 마이그레이션할 수 있음
두 클러스터 간에 토픽 설정, 파티션, 컨슈머 오프셋, ACL 모두 동기화되기 때문에 장애 발생 시 복구 시간이 짧아짐
원본 클러스터에서 대상 클러스터로의 방향성 있는 흐름을 정의하여 대상 클러스터에서 미러링되는 파티션의 리더를 맡고 있는 브로커들을 해당 소스 클러스터 리더 브로커로부터 파티션 데이터를 읽어오는 반면 대상 클러스터의 팔로워들은 일반적인 카프카 복제 메커니즘을 사용하여 리더 브로커로부터 데이터를 복제해 옴
미러링되는 토픽들은 대상 클러스터에서 읽기 전용으로 표시되므로 이 토픽들로는 레코드를 쓸 수 없음
카프카 커넥트 클러스터와 같은 것을 분리할 필요가 없고, 카프카 외부에서 돌아가는 다른 툴들보다 더 성능이 좋아 운영이 더 단순해짐
MRC와 달리 클러스터 링킹에는 동기적 복제 옵션이 없고 클라이언트 장애 복구 작업 역시 수동으로 해주어야 함
불안정하고 높은 지연을 가진 네트워크로 연결되어 있는 서로 멀리 떨어진 데이터센터에 사용될 수 있고 데이터센터 사이에 한번씩만 복제를 수행하여 데이터센터 간 트래픽을 줄일 수 있음
클러스터 마이그레이션이나 토픽 공유와 같은 활용 사례에 적절함