02.변수와 자료형
해당 게시글은 Do it! 자바 프로그래밍 입문 교재를 정리한 내용입니다.
# Chapter 02 - 변수와 자료형
# Java 변수
# Java 변수 선언, 초기화
- 초기화 : 변수의 선언과 동시에 값을 대입
| |
- 변수 이름 정하기
| 제약사항 | 예시 |
|---|---|
| 영문자, 숫자 사용 특수문자는 $, _만 | g_level (O), count100 (O) _master (O), $won (O) |
| 숫자로 시작 불가 | 27day (X), 1abc (X) |
| 예약어 사용 불가 | while, int, break, … |
변수를 선언한다 = 선언한 변수 이름으로 어떤 위치에 있는 메모리를 얼마만큼의 크기로 사용하겠다.
1byte = 8bits
| 정수형 | 문자형 | 실수형 | 논리형 | |
|---|---|---|---|---|
| 1바이트 | byte | - | - | boolean |
| 2바이트 | short | char | - | - |
| 4바이트 | int | - | float | - |
| 8바이트 | long | - | double | - |
# Java 자료형
# 정수형
- 자바에서 정수 값 연산 시 4바이트를 기본 단위로 사용. 모든 정수 값을 기본으로 int형으로 처리. 따라서 다른 자료형이라면 그를 표시해야함.
| |
# 문자형
자바의 기본 인코딩 방식은 모든 문자를 2바이트로 표현하는 UTF-16
자바에서는 따옴표(
'')와 쌍따옴표("") 구분하자. 따옴표가 문자형, char, 쌍따옴표가 문자열, string인 듯 하다.아스키 코드 : 영문자, 소문자, 특수 문자 등을 나타내는 문자 세트, 1바이트만 사용
유니코드(unicode) : 영어 이외에 한글이나 다른 언어 문자는 복잡하고 다양해서 2바이트 이상을 사용하게 됨. 그래서 각 언어의 표준 인코딩을 정의해놓은 것. 유니코드의 1바이트는 아스키 코드 값과 호환되면서 그 밖의 문자를 2바이트나 그 이상의 조합으로 표현. 자바는 유니코드에 기반하여 문자를 표현. 따라서, 자바의 문자 자료형인 char형은 2바이트 사용
| |
# 문자형 - 유니코드
유니코드를 표현하는 인코딩 방법은 UTF-8, UTF-16이 있음
자바의 기본 인코딩 방식은 모든 문자를 2바이트로 표현하는 UTF-16
모두 2바이트로 표현하니까 알파벳 같은 자료(1바이트 자료)를 저장하는 경우 낭비가 있을 수 있음. 반면에, UTF-8은 각 문자마다 1바이트에서 4바이트를 사용하여 문자를 나타내는 방식임. 따라서, UTF-8은 UTF-16에 비해 메모리 낭비가 적고 전송 속도가 빠름. 이러한 특성으로 인터넷에서 많이 사용 (예를 들어, HTML emmet 해보면 UTF-8로 나옴)
\u를 붙히고 뒤에 유니코드를 적는다.한글 유니코드에서 코드 참조
| |
# 실수형
부동 소수점 방식 사용
0.1은1.0 X 10^-1로 표현 가능. 1.0이 가수, 10이 밑수, 제곱수가 지수자바에서 실수는 double형을 기본으로 사용
기본이 double이니까 float 사용하면 식별자
F또는f를 붙혀야함
float형 : 부호 1비트, 지수부 8비트, 가수부 23비트 = 총 32비트(4바이트)
double형 : 부호 1비트, 지수부 11비트, 가수부 52비트 = 총 64비트(8바이트)
| |
정확하게 1001로 떨어지지 않는 이유는 순환소수 문제이다. 다음 코딩애플 자바스크립트 LEVEL2의 부동소수점 부가 설명을 참고하도록 하자.
# 논리형
boolean 변수명boolean형 변수는 1바이트 값으로 저장, true / false만 가짐
# 자료형 추론
자바 10부터 생긴 문법
자바스크립트에 var 같은 거임. 자료형을 정확히 명시 안하고도 변수를 사용가능한 것
지역 변수 자료형 추론(local variable type inference) 라고 한다. 변수에 대입되는 자료를 보고 컴파일러가 추측 가능
단, 자바스크립트의 var과는 다르다. 자바스크립트의 var는 재선언, 재할당 모두 가능했지만, 자바의 var는 재선언이 불가능하다. 추가로, var로 자료형 없이 변수를 선언하려면 지역 변수만 가능하다. 지역 변수는 프로그램의 {}의 내에서 사용할 수 있는 변수이다. 즉, 자바스크립트의 var은 function 스코프였는데, 자바의 var는 block 스코프이다.
| |
# Java 상수
자바스크립트에서는 const 썼는데, 자바에서는 final 예약어 사용
재선언, 재할당 당연히 불가. 처음에 할당 안하고 써도 오류
| |
| |
# Java 리터럴
리터럴(literal)은 프로그램에서 사용하는 모든 숫자, 문자, 논리값을 일컫는 말
리터럴 혹은 리터럴 상수라고 함
리터럴은 프로그램이 시작할 때 시스템에 같이 로딩되어 특정 메모리 공간인 상수 풀(constant pool)에 놓인다. 예를 들어, int num = 3;에서 값인 3이 메모리 공간 어딘가에 존재해야, num 변수에 그 값을 복사할 수 있다. 즉, 숫자가 변수에 대입되는 과정은 일단 숫자 값이 어딘가 메모리에 써져 있어야 하고, 이 값이 다시 변수 메모리에 복사되는 것이다.
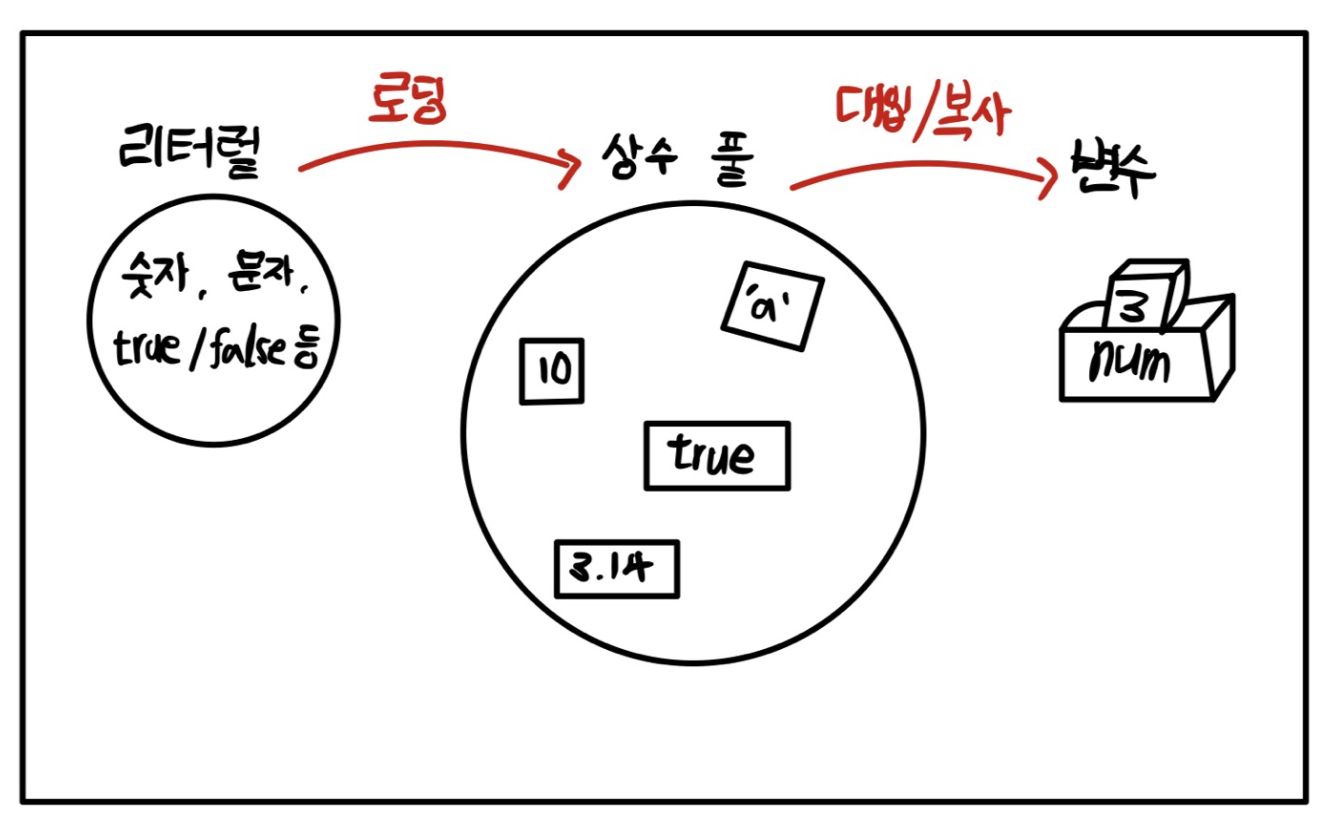
long형에서 식별자 L을 사용해주는 이유가 이때문이다. 자바에서 정수를 표현하는 메모리의 기본 크기는 4바이트인데, 상수 풀에서도 마찬가지다. 리터럴은 int형으로 처리되는데 long형은 4바이트 크기에 들어갈 수 없어서 8바이트로 처리하라고 컴파일러에게 알려주어야 한다. 이 때문에 이 리터럴은 long형으로 저장되어야 한다는 의미로 리터럴 뒤에 식별자 L 이나 l을 붙혀주는 것이다.
# Java 형 변환
형 변환 기본 원칙 (작고 덜 정밀 -> 크고 더 정밀은 자동)
바이트 크기가 작은 자료형 -> 큰 자료형 : 자동으로 형 변환
덜 정밀한 자료형 -> 더 정밀한 자료형 : 자동으로 형 변환
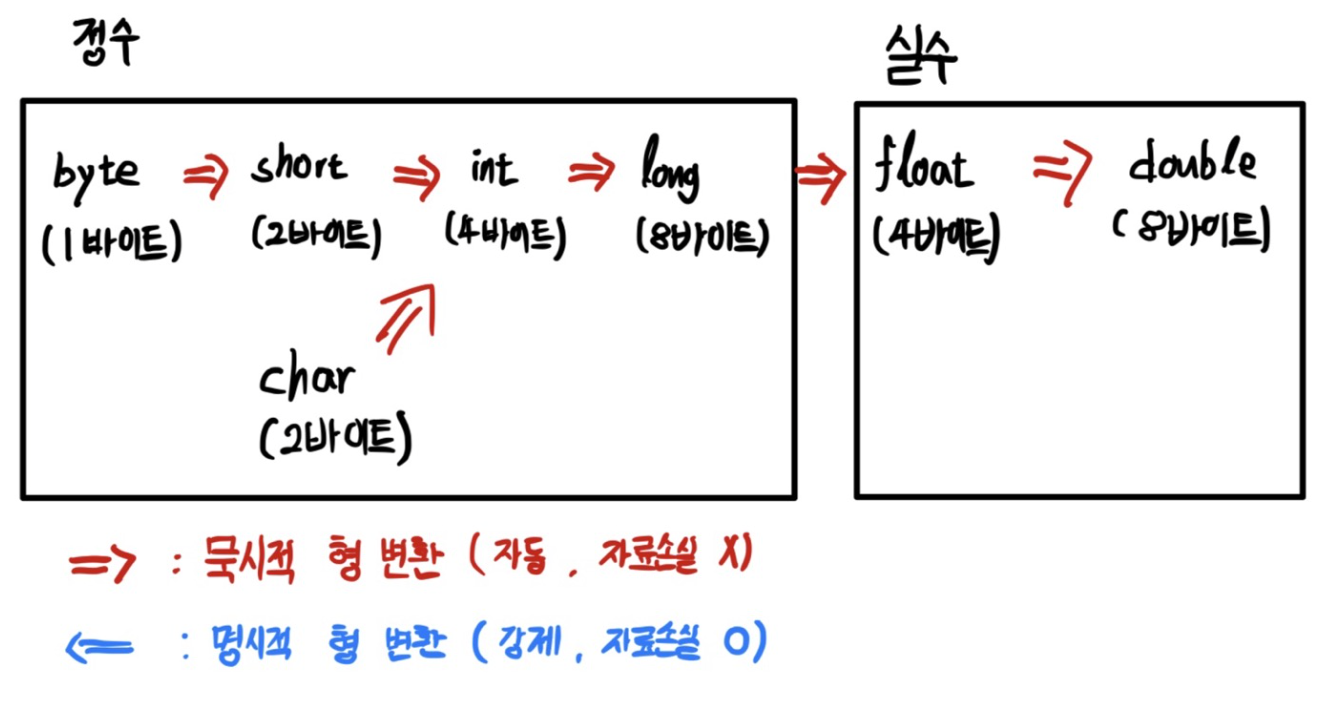
# 묵시적 형 변환 (자동)
- 바이트 크기가 작은 자료형 -> 큰 자료형으로 대입하는 경우
| |
1바이트 -> 4바이트이므로 자료 손실 없이 다 저장됨. 남은 3바이트는 0으로 채워짐
- 덜 정밀한 자료형 -> 더 정밀한 자료형으로 대입하는 경우
| |
4바이트 -> 4바이트이지만, float 자료형이 더 정밀하게 표현가능해서 변환됨
- 연산 중 자동 형 변환
| |
대입 전 float + int 해서 float형으로 먼저 되고, float -> double로 형 변환 됨.
# 명시적 형 변환 (강제)
- 바이트 크기가 큰 자료형 -> 작은 자료형
| |
4바이트 -> 1바이트이므로 자료 손실 발생 가능하다.
예를 들어, 10은 1바이트에 표현 가능하니까 자료손실 X
하지만, 1000의 경우 byte 범위 (-128~127) 벗어나니까 자료손실 O
- 더 정밀한 자료형 -> 덜 정밀한 자료형
| |
더 정밀 -> 덜 정밀이니까 자료 손실 발생 가능. 실수의 소수점 이하 부분이 생략되고 정수 부분만 대입되는 것을 확인 가능
- 연산 중 형 변환
| |
형 변환이 언제 이루어지는 지도 key point. 위에는 형 변환을 하고 더하기 때문에 소수점 아래를 버려버리면 1 + 0 = 1의 결과가 나오고, 아래에는 더한 이후 형 변환을 하기 때문에 1.2 + 0.9 = 2.1을 소수점 아래 버리면 2이다.